
GraphQL
CrafterCMS provides built-in support for GraphQL to query content in any site without writing additional code. Below you’ll find more information on working with GraphQL and how to customize the built-in GraphQL schema
Working with GraphQL
CrafterCMS provides built-in support for GraphQL to query content in any project without writing additional code. A GraphQL schema is generated independently for each project based on the content-type configuration that has been created using Crafter Studio, and the schema is automatically updated after any change is detected.
To implement a project that uses GraphQL you would follow a workflow like this:
Create a new project (if needed, for existing projects skip to step number 3)
Define the content model for your project
Obtain the GraphQL schema for your project, you can use the provided GraphiQL client or any third party client
Develop GraphQL queries to use in your project or external app
All content changes made by authors in Crafter Studio will be immediately available in GraphQL queries.
When a change is made in the content model, for example adding a new field or creating a new content-type, the GraphQL schema will be rebuilt to reflect the same changes. So for a CrafterCMS projecct that uses GraphQL queries the development process would look like this:
Developers define the base content model
Developers define the site base GraphQL queries to use the latest schema
Content authors create content based on the model
Publishers review & approve the author’s work
Publishers publish to live both the content model configuration & the content updates
Crafter Deployer will handle the GraphQL schema rebuild in delivery
You can also use the CrafterCMS GraphQL API from an external project or application, however in this case you will need to handle the schema reload using third party tools.
Using GraphiQL in Crafter Studio
GraphiQL is a simple GraphQL client that you can use in Crafter Studio to run GraphQL queries and explore the schema documentation for a site without the need of any other tool. To access GraphiQL follow these steps:
Login to Crafter Studio
Click the name of your project from the
Projectsscreen and open the left sidebarClick
Project Toolsin the left sidebarClick
GraphiQLin the left sidebar
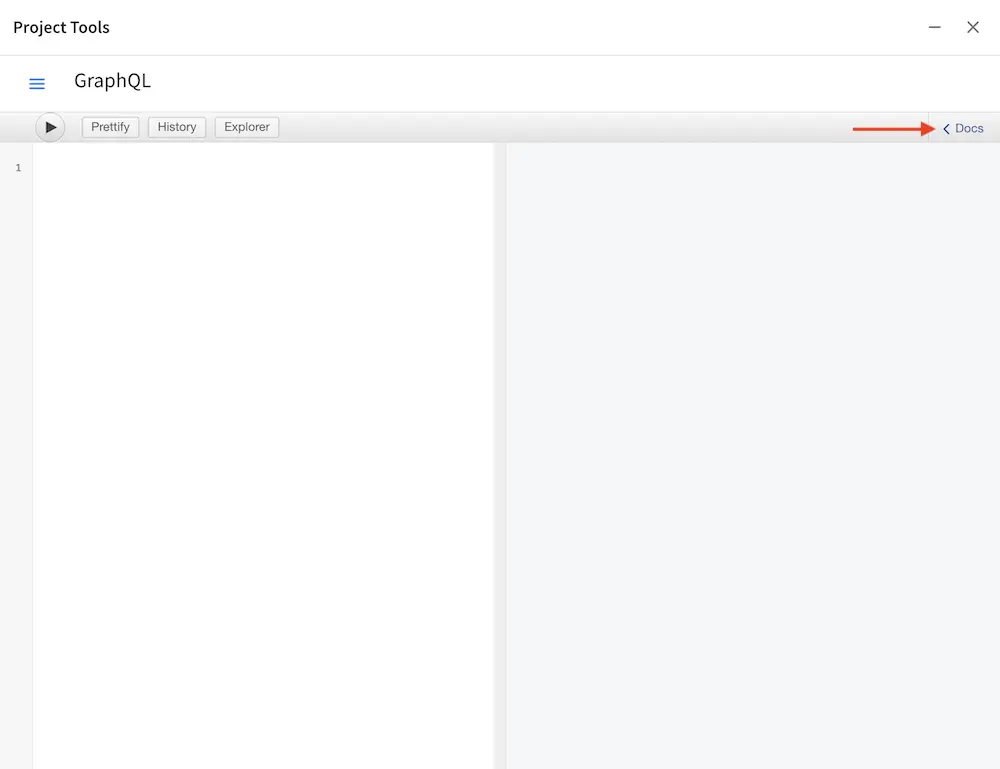
To explore the GraphQL schema you can click the Docs icon on the right side:
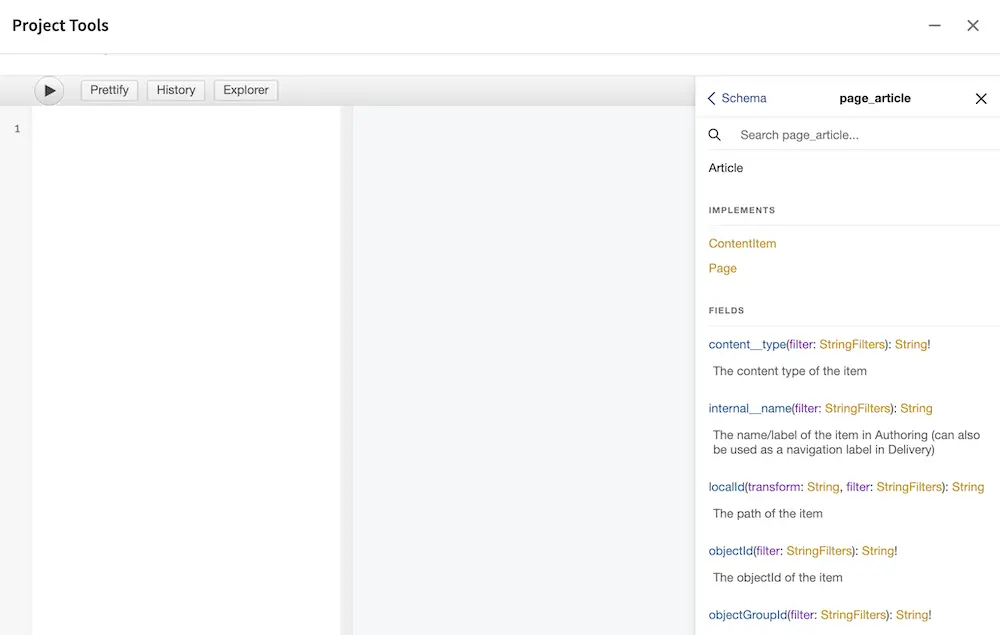
GraphiQL provides a convenient search navigation to quickly find a specific type or field:
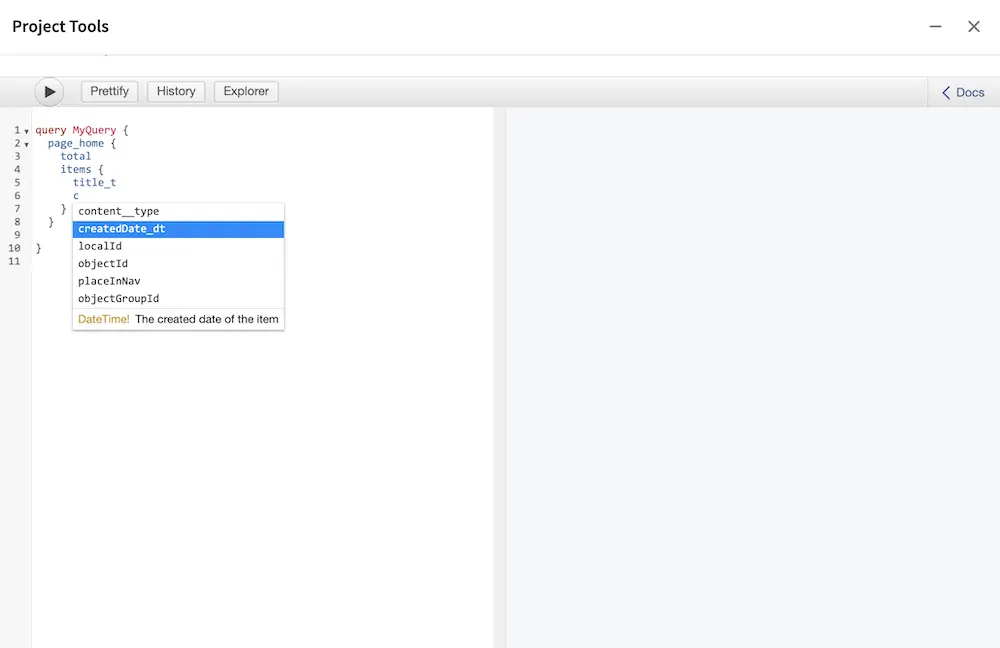
To test GraphQL queries type them in the left text editor, GraphiQL will provide suggestions and validate the query against the schema in real time.
Note
If the GraphQL server host name used is not localhost, the <graphql-server-url /> in your proxy configuration file needs to be set to the appropriate url. For more information on the proxy configuration file, see: Proxy Configuration
GraphQL Examples
Here you can find some examples on how to query content using GraphQL. The following examples use the built-in
Website Editorial blueprint but the same concepts apply to any CrafterCMS site.
For each content-type in the site you will find a field in the root Query, the name of the field is based on the
name of the content-type so for /page/article the field will be page_article.
These fields contain two sub-fields, one is the total number of items found by the query and the other is a list
of items.
Note
Because GraphQL only supports the underscore _ character besides alphanumeric for names, if your content-type or
field name contains the dash - character it will be replaced with a double underscore __. To avoid
unnecessary long names it is suggested to use only _ or camelCase notation if possible.
One of simplest GraphQL queries you can run in CrafterCMS sites is to find all items of a given content-type.
/page/article items 1# root query
2{
3 # query for content-type '/page/article'
4 page_article {
5 total # total number of items found
6 items { # list of items found
7 # content-type fields that will be returned
8 # (names are based on the content-type configuration)
9 title
10 author
11 date_dt
12 }
13 }
14}
You can also run queries to find all pages, components or content items (both pages and components).
1# root query
2{
3 # query for all pages
4 pages {
5 total # total number of items found
6 items { # list of items found
7 # the page fields that will be returned
8 content__type
9 localId
10 createdDate_dt
11 lastModifiedDate_dt
12 placeInNav
13 orderDefault_f
14 navLabel
15 }
16 }
17}
1# root query
2{
3 # query for all pages
4 components {
5 total # total number of items found
6 items { # list of items found
7 # the component fields that will be returned
8 content__type
9 localId
10 createdDate_dt
11 lastModifiedDate_dt
12 }
13 }
14}
1# root query
2{
3 # query for all pages
4 contentItems {
5 total # total number of items found
6 items { # list of items found
7 # the content item fields that will be returned
8 content__type
9 localId
10 createdDate_dt
11 lastModifiedDate_dt
12 }
13 }
14}
As you can expect if there are too many items for a given query the result will be too large, so you can also
implement pagination using the offset and limit parameters. For example the following query
will return only the first five items found.
/page/article 1# root query
2{
3 # query for content-type '/page/article'
4 page_article(offset: 0, limit: 5) {
5 total # total number of items found
6 items { # list of items found
7 # content-type fields that will be returned
8 # (names are based on the content-type configuration)
9 title
10 author
11 date_dt
12 }
13 }
14}
By default all items will be sorted using the lastModifiedDate_dt in descending order, you can change it by using
the sortBy and sortOrder parameters. For example you can use the date_dt field that is specific for the
/page/article content-type to sort.
/page/article 1# root query
2{
3 # query for content-type '/page/article'
4 page_article (offset: 0, limit: 5, sortBy: "date_dt", sortOrder: ASC) {
5 total # total number of items found
6 items { # list of items found
7 # content-type fields that will be returned
8 # (names are based on the content-type configuration)
9 title
10 author
11 date_dt
12 }
13 }
14}
Besides finding all items for a specific content-type, it is also possible to filter the results using one or more fields in the query. Fields will have different filters depending on their type, for example you can find items for a specific author.
/page/article 1# root query
2{
3 # query for content-type '/page/article'
4 page_article (offset: 0, limit: 5, sortBy: "date_dt", sortOrder: ASC) {
5 total # total number of items found
6 items { # list of items found
7 # content-type fields that will be returned
8 # (names are based on the content-type configuration)
9 title
10 # only return articles from this author
11 author (filter: { matches: "Jane" })
12 date_dt
13 }
14 }
15}
Additionally you can create complex filters using expressions like and, or and not for any field:
1# Root query
2{
3 page_article {
4 total
5 items {
6 title
7 author
8 date_dt
9 # Filter articles that are not featured
10 featured_b (
11 filter: {
12 not: [
13 {
14 equals: true
15 }
16 ]
17 }
18 )
19 # Filter articles from category style or health
20 categories {
21 item {
22 key (
23 filter: {
24 or: [
25 {
26 matches: "style"
27 },
28 {
29 matches: "health"
30 }
31 ]
32 }
33 )
34 value_smv
35 }
36 }
37 }
38 }
39}
You can also include fields from child components in your model, this applies to fields like node-selector,
checkbox-group and repeat groups. Filters can also be added to fields from child components.
/page/article using child components 1# root query
2{
3 # query for content-type '/page/article'
4 page_article (offset: 0, limit: 5, sortBy: "date_dt", sortOrder: ASC) {
5 total # total number of items found
6 items { # list of items found
7 # content-type fields that will be returned
8 # (names are based on the content-type configuration)
9 title
10 # only return articles from this author
11 author (filter: { matches: "Jane" })
12 date_dt
13 categories {
14 item {
15 # only return articles from this category
16 key (filter: { matches: "health" })
17 value_smv
18 }
19 }
20 }
21 }
22}
GraphQL aliases are supported on root level query fields (contentItems, pages, components and content
type fields).
1# root query
2{
3 # query for 2016 articles
4 articlesOf2016: page_article {
5 items {
6 localId(filter: {regex: ".*2016.*"})
7 }
8 },
9 # query for 2017 articles
10 articlesOf2017: page_article {
11 items {
12 localId(filter: {regex: ".*2017.*"})
13 }
14 }
15}
GraphQL fragments are fully supported and can be used inline or as spreads. Using fragments you can simplify
queries by extracting repeated fields or request specific fields for different content-types in as single query:
1# Fragment definition
2fragment CommonFields on ContentItem {
3 localId
4 createdDate_dt
5}
6
7# Root query
8query {
9 page_article {
10 total
11 items {
12 # Fragment spread
13 ... CommonFields
14 title
15 author
16 }
17 }
18
19 component_feature {
20 total
21 items {
22 # Fragment spread
23 ... CommonFields
24 title
25 icon
26 }
27 }
28}
1# Root query
2{
3 contentItems {
4 total
5 items {
6 # Query for fields from the interface
7 localId
8 createdDate_dt
9
10 # Query for fields from specific types
11 ... on page_article {
12 title
13 author
14 }
15
16 ... on component_feature {
17 title
18 icon
19 }
20 }
21 }
22}
For more detailed information about GraphQL you can read the official documentation.
Custom GraphQL Schema
CrafterCMS provides a simple way to customize the built-in GraphQL schema. This feature can be used for integrating external services or transforming values to match special requirements. Once the schema has been customized it is possible to create apps or sites that interact only using GraphQL for getting both authored content & external services.
Note
This guide assumes you are familiar with GraphQL concepts like types, fields, resolvers & fetchers, you can find more information in the GraphQL documentation
After Crafter Engine builds the types corresponding to the Content Types in the site repository it will look for a
Groovy script that allows you to make customizations to the schema before making it available to the clients. By
default the full path of the script is /scripts/graphql/init.groovy.
In this script you will be able to use most of the global variables described in Groovy/Java API (except the ones for the request scope). Additionally there is a global variable specific for this script:
Name |
Description |
Type |
|---|---|---|
schema |
Holds custom types, fields, fetchers & resolvers that
will be added to the GraphQL schema
|
Note
All customizations to the GraphQL schema need to be done programmatically, you can find more details & examples in the GraphQL Java documentation
Example
The following example shows how to customize the schema to integrate a service written in Groovy.
Note
The example uses the public OMDb API that requires a key, to make the code work in your local environment you can get a free key here
Update the site configuration to include the needed information to connect to the OMDb API:
/config/engine/site-config.xml1<site> 2 <omdb> 3 <baseUrl>http://www.omdbapi.com</baseUrl> 4 <apiKey>XXXXXXX</apiKey> 5 </omdb> 6</site>
Update the site context to include a new service bean:
/config/engine/application-context.xml1 <beans xmlns="http://www.springframework.org/schema/beans" 2 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 3 xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd" 4 xmlns:context="http://www.springframework.org/schema/context"> 5 6 <!-- Enable placeholders support --> 7 <context:property-placeholder/> 8 9 <!-- Define the service bean --> 10 <bean id="omdbService" init-method="init" 11 class="org.craftercms.movies.omdb.OmdbService"> 12 <property name="baseUrl" value="${omdb.baseUrl}"/> 13 <property name="apiKey" value="${omdb.apiKey}"/> 14 </bean> 15 </beans>
Add the Groovy class for the service:
/scripts/classes/org/craftercms/movies/omdb/OmdbService.groovy1package org.craftercms.movies.omdb 2 3// include a third-party library for easily calling the API 4@Grab(value='io.github.http-builder-ng:http-builder-ng-core:1.0.4', initClass=false) 5import groovyx.net.http.HttpBuilder 6 7class OmdbService { 8 9 // the base URL for all API calls 10 String baseUrl 11 12 // the API key needed for the calls 13 String apiKey 14 15 // The http client 16 HttpBuilder http 17 18 // creates an instance of the http client with the configured base URL 19 def init() { 20 http = HttpBuilder.configure { 21 request.uri = baseUrl 22 } 23 } 24 25 // performs a search call, returns the entries as maps 26 def search(String title) { 27 return [ 28 http.get() { 29 // include the needed parameters 30 request.uri.query = [ apiKey: apiKey, t: title ] 31 } 32 ].flatten() // return a list even if the API only returns a single entry 33 } 34 35}
Note
Notice that the service is not performing any mapping or transformation to the values returned by the API. It will only parse the response from JSON into Groovy map instances. This means that the GraphQL schema needs to match the field names returned by the API.
Define the GraphQL schema to use:
First you need to know what the API will return to create a matching schema, in any browser or REST client execute a call to
http://www.omdbapi.com/?t=XXXX&apikey=XXXXXXX. The result will look like this:OMDb API response for movies1{ 2 "Title": "Hackers", 3 "Year": "1995", 4 "Rated": "PG-13", 5 "Released": "15 Sep 1995", 6 "Runtime": "107 min", 7 "Genre": "Comedy, Crime, Drama, Thriller", 8 "Director": "Iain Softley", 9 "Writer": "Rafael Moreu", 10 "Actors": "Jonny Lee Miller, Angelina Jolie, Jesse Bradford, Matthew Lillard", 11 "Plot": "Hackers are blamed for making a virus that will capsize five oil tankers.", 12 "Language": "English, Italian, Japanese, Russian", 13 "Country": "USA", 14 "Awards": "N/A", 15 "Poster": "https://m.media-amazon.com/images/M/MV5BNmExMTkyYjItZTg0YS00NWYzLTkwMjItZWJiOWQ2M2ZkYjE4XkEyXkFqcGdeQXVyMTQxNzMzNDI@._V1_SX300.jpg", 16 "Ratings": [ 17 { 18 "Source": "Internet Movie Database", 19 "Value": "6.2/10" 20 }, 21 { 22 "Source": "Rotten Tomatoes", 23 "Value": "33%" 24 }, 25 { 26 "Source": "Metacritic", 27 "Value": "46/100" 28 } 29 ], 30 "Metascore": "46", 31 "imdbRating": "6.2", 32 "imdbVotes": "62,125", 33 "imdbID": "tt0113243", 34 "Type": "movie", 35 "DVD": "24 Apr 2001", 36 "BoxOffice": "N/A", 37 "Production": "MGM", 38 "Website": "N/A", 39 "Response": "True" 40}
OMDb API response for series1{ 2 "Title": "Friends", 3 "Year": "1994–2004", 4 "Rated": "TV-14", 5 "Released": "22 Sep 1994", 6 "Runtime": "22 min", 7 "Genre": "Comedy, Romance", 8 "Director": "N/A", 9 "Writer": "David Crane, Marta Kauffman", 10 "Actors": "Jennifer Aniston, Courteney Cox, Lisa Kudrow, Matt LeBlanc", 11 "Plot": "Follows the personal and professional lives of six twenty to thirty-something-year-old friends living in Manhattan.", 12 "Language": "English, Dutch, Italian, French", 13 "Country": "USA", 14 "Awards": "Won 1 Golden Globe. Another 68 wins & 211 nominations.", 15 "Poster": "https://m.media-amazon.com/images/M/MV5BNDVkYjU0MzctMWRmZi00NTkxLTgwZWEtOWVhYjZlYjllYmU4XkEyXkFqcGdeQXVyNTA4NzY1MzY@._V1_SX300.jpg", 16 "Ratings": [ 17 { 18 "Source": "Internet Movie Database", 19 "Value": "8.9/10" 20 } 21 ], 22 "Metascore": "N/A", 23 "imdbRating": "8.9", 24 "imdbVotes": "696,324", 25 "imdbID": "tt0108778", 26 "Type": "series", 27 "totalSeasons": "10", 28 "Response": "True" 29}
The API also has support for single episodes but those will not be included in this example. Not all fields returned by the API might be needed in the GraphQL schema, for this example we will include a small subset.
The first step is to define a generic entry type that includes all common fields present in movies and series:
GraphQL interface for all entries1interface OmdbEntry { 2 Title: String! 3 Genre: String! 4 Plot: String! 5 Actors: [String!] 6}
Notice that the API returns a single string for the
Actorsfields but in the GraphQL schema it will be defined as a list of strings, a custom data fetcher will handle this transformation.- Next step is to define the concrete types for movies and series, those will have all fields from the parent
type but include new ones:
GraphQL type for movies1type OmdbMovie implements OmdbEntry { 2 Title: String! 3 Genre: String! 4 Plot: String! 5 Actors: [String!] 6 7 Production: String! 8}
GraphQL type for series1type OmdbSeries implements OmdbEntry { 2 Title: String! 3 Genre: String! 4 Plot: String! 5 Actors: [String!] 6 7 totalSeasons: Int! 8}
Finally the service call will be exposed using a wrapper type:
GraphQL type for the service1type OmdbService { 2 3 search(title: String): [OmdbEntry!] 4 5}
Add the GraphQL schema customizations to create the schema defined in the previous step:
/script/graphql/init.groovy1package graphql 2 3import static graphql.Scalars.GraphQLInt 4import static graphql.Scalars.GraphQLString 5import static graphql.schema.GraphQLArgument.newArgument 6import static graphql.schema.GraphQLFieldDefinition.newFieldDefinition 7import static graphql.schema.GraphQLInterfaceType.newInterface 8import static graphql.schema.GraphQLList.list 9import static graphql.schema.GraphQLNonNull.nonNull 10import static graphql.schema.GraphQLObjectType.newObject 11 12// Define the fields common to all types 13def entryFields = [ 14 newFieldDefinition() 15 .name('Title') 16 .description('The title of the entry') 17 .type(nonNull(GraphQLString)) 18 .build(), 19 newFieldDefinition() 20 .name('Genre') 21 .description('The genre of the entry') 22 .type(nonNull(GraphQLString)) 23 .build(), 24 newFieldDefinition() 25 .name('Plot') 26 .description('The plot of the entry') 27 .type(nonNull(GraphQLString)) 28 .build(), 29 newFieldDefinition() 30 .name('Actors') 31 .description('The main cast of the entry') 32 .type(list(nonNull(GraphQLString))) 33 .build() 34] 35 36// Define the parent type 37def entryType = newInterface() 38 .name('OmdbEntry') 39 .description('The generic entry returned by the API') 40 .fields(entryFields) 41 .build() 42 43// Define the type for movies 44def movieType = newObject() 45 .name('OmdbMovie') 46 .description('The entry returned for movies by the API') 47 // Use the parent type 48 .withInterface(entryType) 49 // GraphQL required to repeat all fields from the interface 50 .fields(entryFields) 51 .field(newFieldDefinition() 52 .name('Production') 53 .description('The studio of the entry') 54 .type(nonNull(GraphQLString)) 55 ) 56 .build() 57 58def seriesType = newObject() 59 .name('OmdbSeries') 60 .description('The entry returned for series by the API') 61 // Use the parent type 62 .withInterface(entryType) 63 // GraphQL required to repeat all fields from the interface 64 .fields(entryFields) 65 .field(newFieldDefinition() 66 .name('totalSeasons') 67 .description('The number of seasons of the entry') 68 .type(nonNull(GraphQLInt)) 69 ) 70 .build() 71 72// Add the resolver for the new types 73schema.resolver('OmdbEntry', { env -> 74 // The API returns the type as a field 75 switch(env.object.Type) { 76 case 'movie': 77 return movieType 78 case 'series': 79 return seriesType 80 } 81}) 82 83// Add the child types to the schema 84// (this is needed because they are not used directly in any field) 85schema.additionalTypes(movieType, seriesType) 86 87// Add the new fields to the top level type 88schema.field(newFieldDefinition() 89 .name('omdb') // this field is used to wrap the service calls 90 .description('All operations related to the OMDb API') 91 .type(newObject() // inline type definition 92 .name('OmdbService') 93 .description('Exposes the OMDb Service') 94 .field(newFieldDefinition() 95 .name('search') 96 .description('Performs a search by title') 97 // uses the parent type, the resolver will define the concrete type 98 .type(list(nonNull(entryType))) 99 .argument(newArgument() 100 .name('title') 101 .description("The title to search") 102 .type(GraphQLString) 103 ) 104 ) 105 ) 106) 107 108// Add the fetcher for the search field, 109schema.fetcher('OmdbService', 'search', { env -> 110 // calls the Groovy bean passing the needed parameters 111 applicationContext.omdbService.search(env.getArgument('title')) 112}) 113 114// Define a fetcher to split the value returned by the API for the Actors 115def actorsFetcher = { env -> env.source.Actors?.split(',')*.trim() } 116 117// Add the fetcher to the concrete types 118schema.fetcher('OmdbMovie', 'Actors', actorsFetcher) 119schema.fetcher('OmdbSeries', 'Actors', actorsFetcher)
Verify how the GraphQL schema has changed:
The new field
odmb.searchis now available and can be called with different parameters, you can requests different fields depending on the type of each result.For movies the
Productionfield is returned: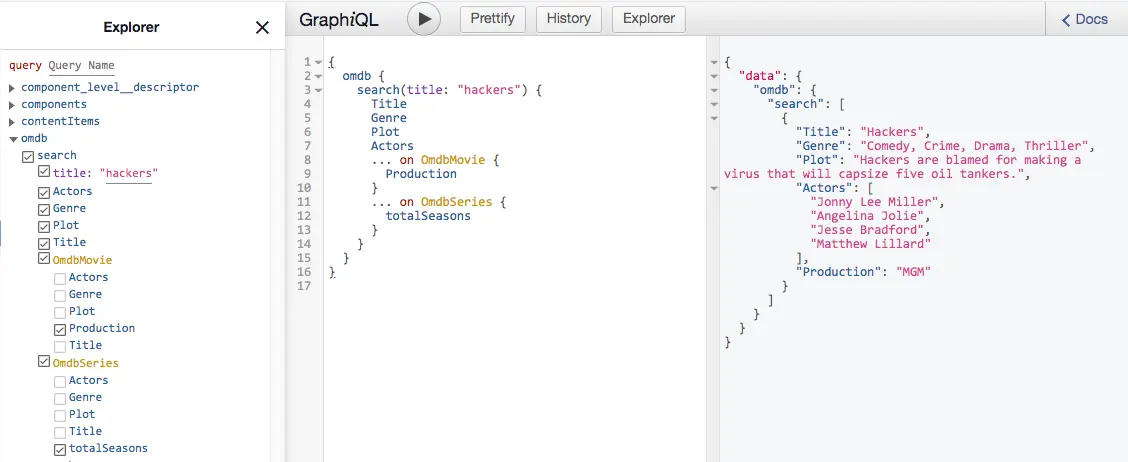
For series the
totalSeasonsis returned: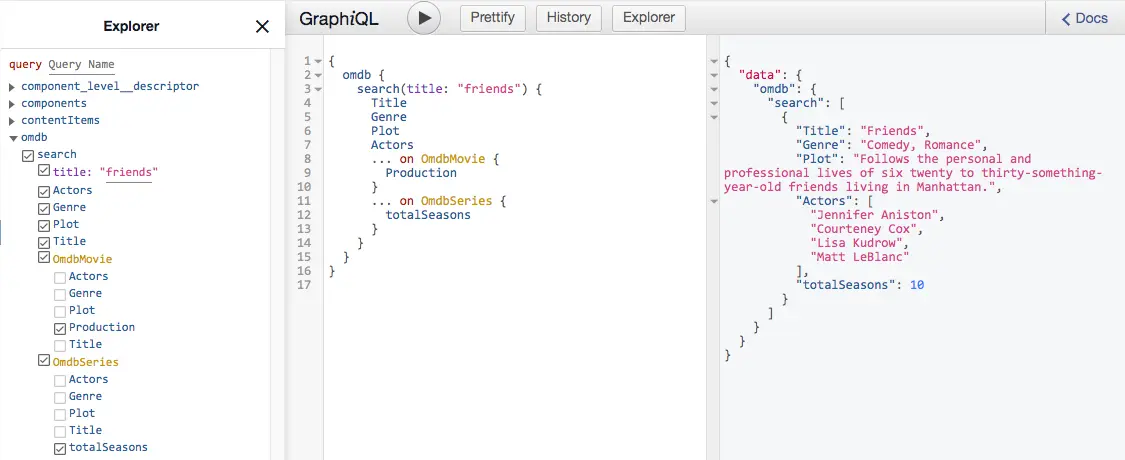
This is a very simple example that shows the basic features to integrate a service in the schema, but it is possible to use any GraphQL feature such as mutations to wrap a full REST API or database.