
Search
Search API
To perform content queries, you need to use the client provided by Crafter Engine; the bean name is
searchClient and can be used in any Groovy script.
Note
The old client searchService is now deprecated, and searchClient should be used.
You can find the interface for this service in the JavaDoc.
Content Search Indexing
Search indexing is the collecting, parsing, and storing of data to enable search across content in CrafterCMS. CrafterCMS indexes content items as follows:
A full text index of any document that has a MIME type that matches the configured list of MIME types.
See MIME types for more information on configuring MIME types used for indexing.Indexing of any remote document that matches the configured list of remote documents pattern.
See Remote Documents Path Pattern for more information on configuring remote documents pattern used for indexing.Indexing of jacketed documents (binary documents with additional added metadata) with anything that matches the configured pattern.
See Metadata Path Pattern for more information on configuring metadata path patterns used for indexing.
Indexing is done differently in the authoring environment vs the delivery environment. To this end, indexing of documents in authoring and indexing of documents in delivery each have their own configuration.
The default behavior when a document cannot be indexed is that the Deployer logs the error and moves on. Processed commits files are updated, and the Deployer never revisits the indexing unless a future publish requires it to, or, a re-process API is called, such as the deployTarget API
If the deployment as a whole cannot be completed due to a catastrophic exception, then all content including documents will be re-processed until the deployment succeeds. By default the Git Diff process is configured to update the processed commits regardless of success or failure. Some deployments set this to false and force the processor chain to be successful before updating processed commits (via the GitUpdateCommits Processor). See Deployer Processors for more information on available Deployer processors.
Delivery Search Indexing
Delivery indexing is done to enable search and search-based features for the delivery project/site. This is configurable per project/site, and the index is tuned to help end-users use the project/site. Developers working on projects/sites will leverage this to perform search and add search-based features. Tuning this index might make sense for specific use cases where the defaults are not enough.
Creating Queries
Depending on the complexity of the queries there are two ways to create the queries:
Query DSL
This follows the same structure that OpenSearch uses for the REST API, see their query documentation. This method is suitable for constant or simple queries that don’t require too much configuration.
1// No imports are required for this method
2
3// Execute the query using inline builders
4def searchResponse = searchClient.search(r -> r
5 .query(q -> q
6 .bool(b -> b
7 .should(s -> s
8 .match(m -> m
9 .field('content-type')
10 .query(v -> v
11 .stringValue('/component/article')
12 )
13 )
14 )
15 .should(s -> s
16 .match(m -> m
17 .field('author')
18 .query(v -> v
19 .stringValue('My User')
20 )
21 )
22 )
23 )
24 )
25, Map)
26
27def itemsFound = searchResponse.hits().total().value()
28def items = searchResponse.hits().hits()*.source()
29
30return items
Note
You can find detailed information for the JSON DSL in the query documentation
Query Builders
You can use all classes available in the official OpenSearch client package to build your queries, more in their java documentation. This method allows you to use builder objects to develop complex logic for building the queries.
1// Import the required classes
2import org.opensearch.client.opensearch.core.SearchRequest
3
4def queryStatement = 'content-type:"/component/article" AND author:"My User"'
5
6// Use the appropriate builders according to your query
7def builder = new SearchRequest.Builder()
8 .query(q -> q
9 .queryString(s -> s
10 .query(queryStatement)
11 )
12 )
13
14// Perform any additional changes to the builder, for example add pagination if required
15if (pagination) {
16 builder
17 .from(pagination.offset)
18 .size(pagination.limit)
19}
20
21// Execute the query
22def searchResponse = searchClient.search(builder.build(), Map)
23
24def itemsFound = searchResponse.hits().total().value()
25def items = searchResponse.hits().hits()*.source()
26
27return items
Note
You can find detailed information for each builder in the java documentation
Examples
Implementing a Faceted Search
It is possible to use aggregations to provide a faceted search to allow users to refine the search results based on one or more fields.
Note
Search offers a variety of aggregations that can be used depending on the type of the fields in your model or the requirements in the UI to display the data, for detailed information visit the official documentation
In this section, we will be using the most basic aggregation terms to provide a faceted search based on the
category of blog articles.
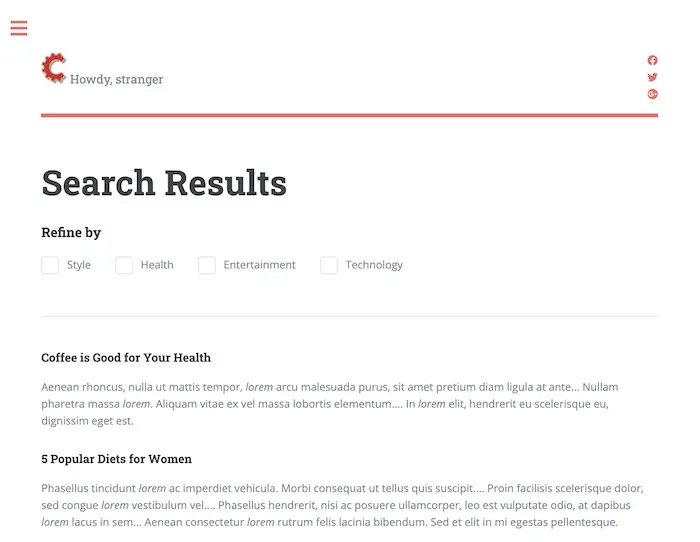
First we must define the fields that will be used for the aggregation, in this case the page model for Article has
a categories field that uses a datasource to get values from a taxonomy in the site. For this case the name of the
field in the index is categories.item.value_smv.
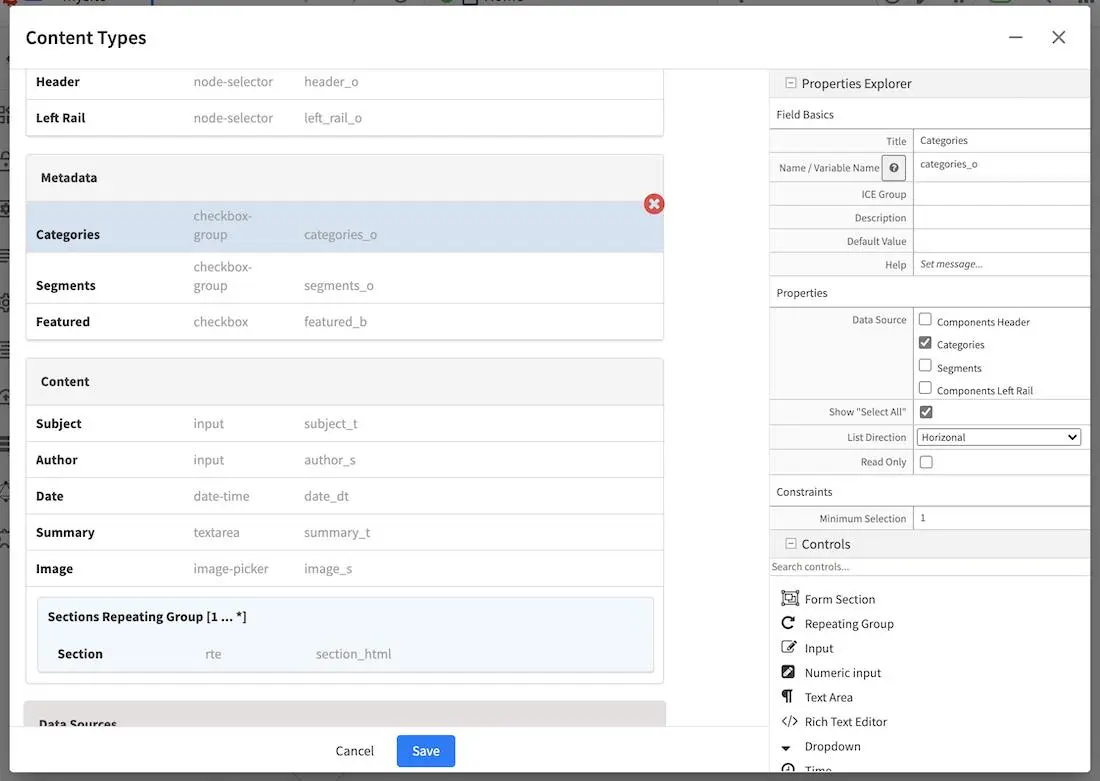
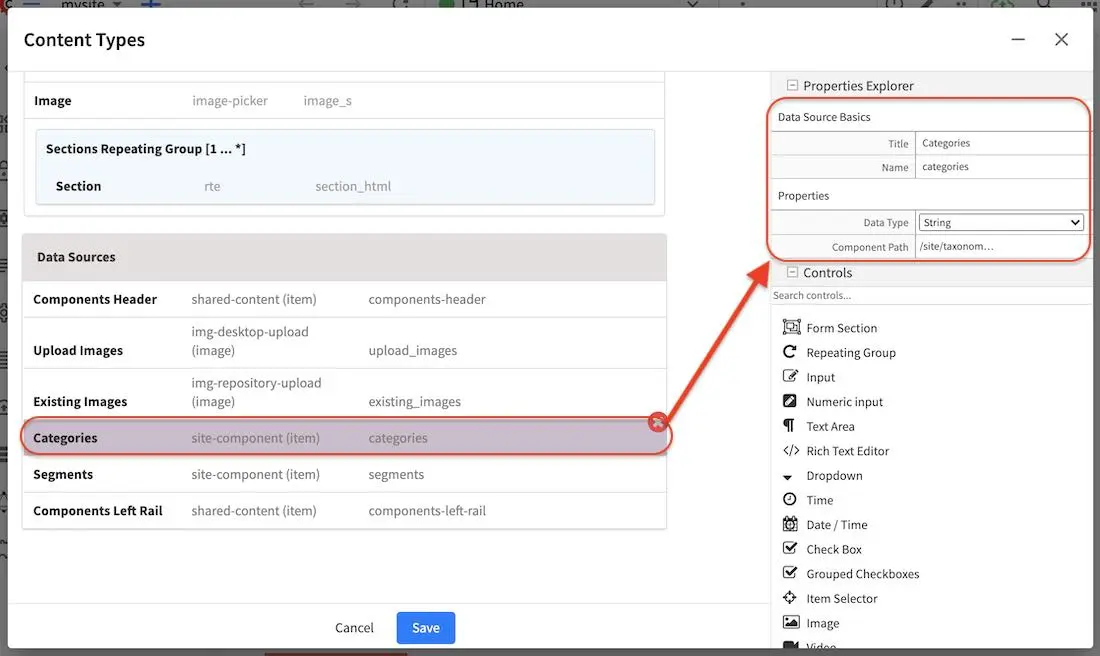
To build the faceted search we must:
Include the appropriate aggregations in the search request
Process the aggregations from the search response
Display the facets in the search result page
Sending Aggregations in the Search Request
Aggregations are added in the request using the aggs key, each aggregation must have a unique name
as key and the configuration depending on the type.
1def result = searchClient.search(r -> r
2 .query(q -> q
3 .queryString(s -> s
4 .query(q as String)
5 )
6 )
7 .from(start)
8 .size(rows)
9 .aggregations('categories', a -> a
10 .terms(t -> t
11 .field(categories.item.value_smv)
12 .minDocCount(1)
13 )
14 )
15, Map)
In the previous example we include a terms aggregation called categories that will return all found values for
the field categories.item.value_smv that have at least 1 article assigned.
Processing Aggregations in the Search Response
Search will return the aggregations in the response under the aggregations field, the contents of each
aggregation will be different depending on the type.
1def facets = [:]
2if(result.aggregations()) {
3 result.aggregations().each { name, agg ->
4 facets[name] = agg.sterms().buckets().array().collect{ [ value: it.key(), count: it.docCount() ] }
5 }
6}
In the previous example we extract the aggregations from the response object to a simple map, this example assumes
that all aggregation will be of type terms so it gets the key and docCount for each value found
(Search calls them buckets).
The result from a query of all existing articles could return something similar to this:
1"facets":{
2 "categories":[
3 { "value":"Entertainment", "count":3 },
4 { "value":"Health", "count":3 },
5 { "value":"Style", "count":1 },
6 { "value":"Technology", "count":1 }
7 ]
8}
According to the given example, if we run our query again including a filter for category with value Entertainment
it will return exactly 3 articles, and in the next query we will get a new set of facets based on those articles.
This is how users can quickly reduce the number of result and find more useful data with less effort.
Displaying Facets in the Search Result Pages
This step will change depending on the technology being used to display all information, it can be done in Freemarker or a SPA using Angular, React or Vue. As an example we will use Handlebars templates that will be rendered using jQuery.
1<script id="search-facets-template" type="text/x-handlebars-template">
2 {{#if facets}}
3 <div class="row uniform">
4 {{#each facets}}
5 <div class="3u 6u(medium) 12u$(small)">
6 <input type="checkbox" id="{{value}}" name="{{value}}" value="{{value}}">
7 <label for="{{value}}">{{value}} ({{count}})</label>
8 </div>
9 {{/each}}
10 </div>
11 {{/if}}
12</script>
13
14<script id="search-results-template" type="text/x-handlebars-template">
15{{#each articles}}
16 <div>
17 <h4><a href="{{url}}">{{title}}</a></h4>
18 {{#if highlight}}
19 <p>{{{highlight}}}</p>
20 {{/if}}
21 </div>
22 {{else}}
23 <p>No results found</p>
24{{/each}}
25</script>
We use the templates to render the results after executing the search
1$.get("/api/search.json", params).done(function(data) {
2 if (data == null) {
3 data = {};
4 }
5 $('#search-facets').html(facetsTemplate({ facets: data.facets.categories }));
6 $('#search-results').html(articlesTemplate(data));
7});
The final step is to trigger a new search when the user selects one of the values in the facets
1$('#search-facets').on('click', 'input', function() {
2var categories = [];
3$('#search-facets input:checked').each(function() {
4categories.push($(this).val());
5});
6
7doSearch(queryParam, categories);
8});
Multi-index Query
CrafterCMS supports querying more than one search index in a single query.
To search your site and other indexes, simply send a search query with a comma separated list of indexes/aliases (pointer to an index). It will then search your site and the other indexes

Remember that all other indexes/aliases to be searched need to be prefixed with the site name like this: SITENAME_{external-index-name}. When sending the query, remove the prefix SITENAME_ from the other indexes/aliases.
Here’s how the query will look like for the above image of a multi-index query for the site acme (the SITENAME), and the CD database index acme_cd-database:
1def result = openSearch.search(new SearchRequest('cd-database').source(builder))
1curl -s -X POST "localhost:8080/api/1/site/search/search?index=cd-database" -d '
2{
3 "query" : {
4 "match_all" : {}
5 }
6}
7'
See here for more information on the Crafter Engine API search.
CrafterCMS supports the following search query parameters:
indices_boost
search_type
allow_no_indices
expand_wildcards
ignore_throttled
ignore_unavailable
See the official docs for more information on the above parameters.
For more information on indices_boost, see index boosting in this article https://opensearch.org/docs/latest/api-reference/search/
Implementing a Type-ahead Service
In this section, we will be looking at how to use a query to provide suggestions as the user types.
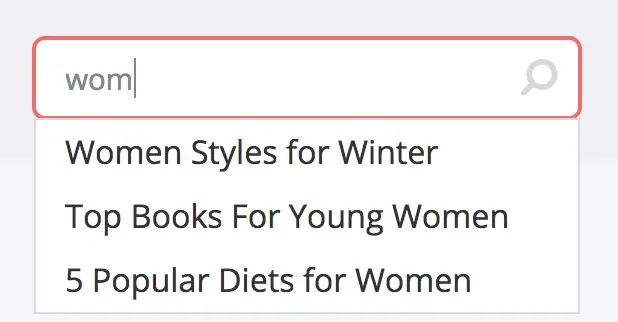
Build the Service
Create a REST service that returns suggestions based on the content in your site.
Requirements
The service will take the user’s current search term and find similar content.
The service will return the results as a list of strings
To create the REST endpoint, place the following Groovy file in your scripts folder
1import org.craftercms.sites.editorial.SuggestionHelper
2
3// Obtain the text from the request parameters
4def term = params.term
5
6def helper = new SuggestionHelper(searchClient)
7
8// Execute the query and process the results
9return helper.getSuggestions(term)
You will also need to create the helper class in the scripts folder
1package org.craftercms.sites.editorial
2
3import org.opensearch.client.opensearch.core.SearchRequest
4import org.craftercms.search.opensearch.client.OpenSearchClientWrapper
5
6class SuggestionHelper {
7
8 static final String DEFAULT_CONTENT_TYPE_QUERY = "content-type:\"/page/article\""
9 static final String DEFAULT_SEARCH_FIELD = "subject_t"
10
11 OpenSearchClientWrapper searchClient
12
13 String contentTypeQuery = DEFAULT_CONTENT_TYPE_QUERY
14 String searchField = DEFAULT_SEARCH_FIELD
15
16 SuggestionHelper(searchClient) {
17 this.searchClient = searchClient
18 }
19
20 def getSuggestions(String term) {
21 def queryStr = "${contentTypeQuery} AND ${searchField}:*${term}*"
22 def result = searchClient.search(SearchRequest.of(r -> r
23 .query(q -> q
24 .queryString(s -> s
25 .query(queryStr)
26 )
27 )
28 ), Map)
29
30 return process(result)
31 }
32
33 def process(result) {
34 def processed = result.hits.hits*.getSourceAsMap().collect { doc ->
35 doc[searchField]
36 }
37 return processed
38 }
39}
Once those files are created and the site context is reloaded you should be able to test the REST endpoint from a browser and get a result similar to this:
http://localhost:8080/api/1/services/suggestions.json?term=men
1[
2 "Men Styles For Winter",
3 "Women Styles for Winter",
4 "Top Books For Young Women",
5 "5 Popular Diets for Women"
6]
Build the UI
The front end experience is built with HTML, JavaScript and specifically AJAX.
Requirements
When the user types a value send a request to the server to get instant results
Display the results and show suggestions about what the user might be looking for
Do not fire a query for every keystroke. This can lead to more load than necessary, instead, batch user keystrokes and send when batch size is hit or when the user stops typing.
You can also integrate any existing library or framework that provides a type-ahead component, for example to use the jQuery UI Autocomplete component you only need to provide the REST endpoint in the configuration:
1$('#search').autocomplete({
2 // Wait for at least this many characters to send the request
3 minLength: 2,
4 source: '/api/1/services/suggestions.json',
5 // Once the user selects a suggestion from the list, redirect to the results page
6 select: function(evt, ui) {
7 window.location.replace("/search-results?q=" + ui.item.value);
8 }
9});