
Studio Clustering 
Crafter Studio can be clustered for high-availability.
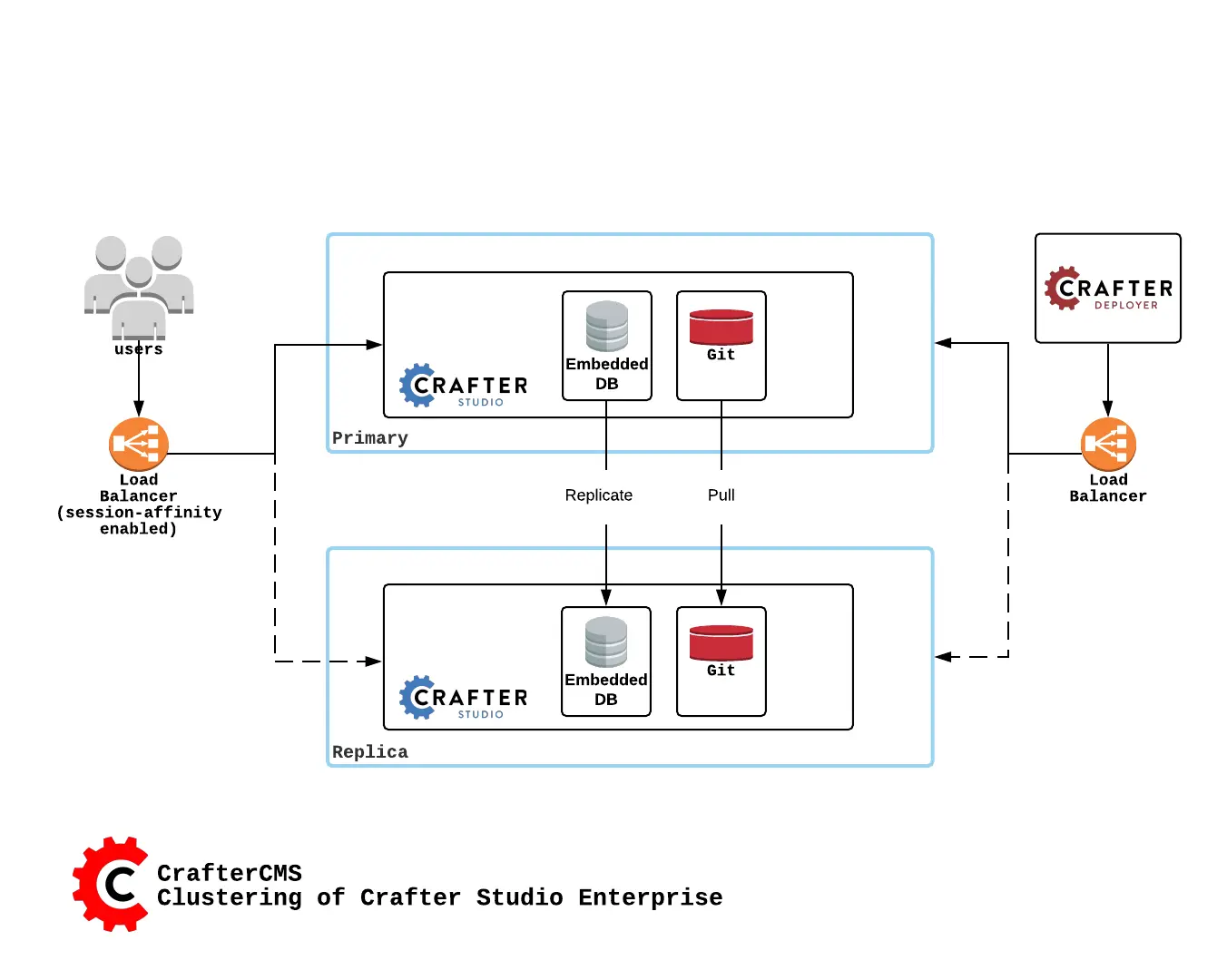
A node is a server running an instance of Crafter Studio and a cluster consists of two or more nodes. In the image above, two Crafter Studio instances are clustered as primary and replica.
When setting up a Studio cluster, a specific node needs to be started first as a reference point, then the other node/s can join and form the cluster. This is known as cluster bootstrapping. Bootstrapping is the first step to introduce a node as Primary Component, which others will see as a reference point to sync up with.
The Primary Component is a central concept on how to ensure that there is no opportunity for database inconsistency or divergence between the nodes in case of a network split. The Primary Component is a set of nodes that communicate with each other over the network and contains the majority of the nodes. There’s no Primary Component yet when starting up a cluster, hence the need of the first node to bootstrap the Component. The other nodes will then look for the existing Primary Component to join.
Note
Studio nodes use an in-memory distributed data store to orchestrate the bootstrapping of the Primary Component, so you don’t need to do it. When the cluster is started, the nodes synchronize through the data store to decide which one does the bootstrapping, and then the rest join the Primary Component.
Once the cluster is up, one node in the cluster is elected to be the primary and the rest of the node(s) as replica(s).
Requirements
Before we begin configuring Studio for clustering, the following must be setup:
A DNS server directing traffic to the primary node, and can failover to the replica node if the primary is not healthy
Configuring Studio Clustering
First, we’ll take a look at an example of how to setup a two node cluster with Studio step by step, then, we’ll take a look at an example of setting up Studio clustering using a Kubernetes deployment
Multi-Region Considerations
For clusters with nodes in multi-regions utilizing S3 buckets, AWS provides solutions for handling multi-region deployments of S3 buckets.
AWS supports access points for managing access to a shared bucket on S3. For more information on Amazon S3 Access Points, see https://docs.aws.amazon.com/AmazonS3/latest/userguide/access-points.html
For clusters with S3 buckets located in multiple AWS regions, Amazon S3 Multi-Region Access Points provide a global endpoint that applications can use to fulfill requests from. For more information on Multi-Region Access Points in Amazon S3, see https://docs.aws.amazon.com/AmazonS3/latest/userguide/MultiRegionAccessPoints.html
AWS S3 also supports bucket replication (S3 replication) irrespective of the region they belong to, which provides data protection against disasters, minimizing latency, etc. For more information on S3 bucket replication for use with multi-region access points, see https://docs.aws.amazon.com/AmazonS3/latest/userguide/MultiRegionAccessPointBucketReplication.html
Here’s some more information on S3 replication: https://aws.amazon.com/about-aws/whats-new/2020/12/amazon-s3-replication-adds-support-two-way-replication/