
Crafter Deployer
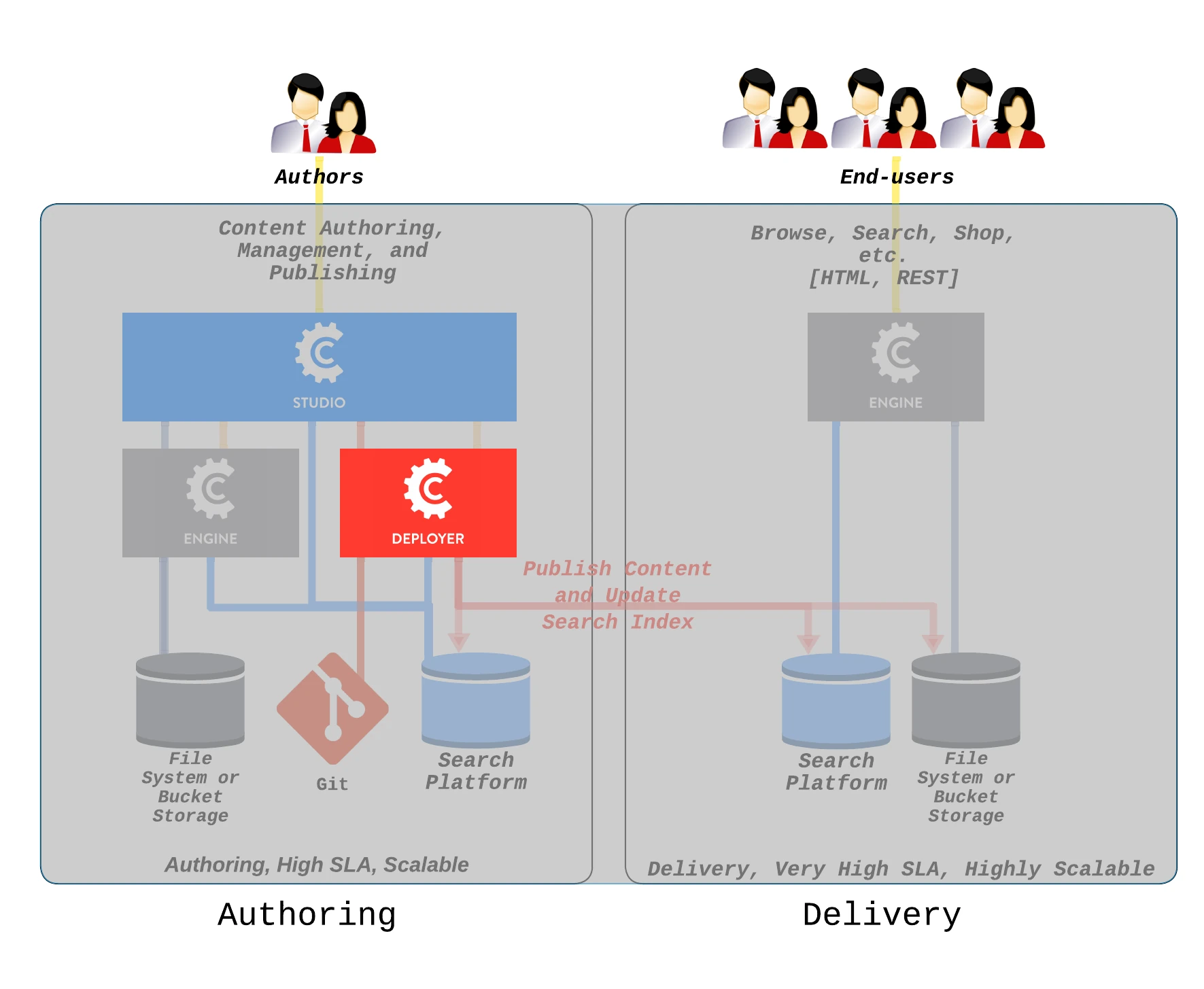
Crafter Deployer is the deployment agent for CrafterCMS.
Crafter Deployer performs indexing and runs scheduled deployments to perform tasks like pushing/pulling content created/edited in Crafter Studio to an external service, executing actions every time a deployment succeeds or fails, sending out deployment email notifications, etc.
Configuration
Configuration Files
Crafter Deployer can be configured at the global level and individual target level.
Global configuration files are in
$CRAFTER_HOME/bin/crafter-deployer/config/, and will be applied to all targets loaded.Individual target configuration files are in
$CRAFTER_HOME/data/deployer/targets/{siteName}-{environment}.yaml
Global Configuration Files
Crafter Deployer has two main property configuration files found in CRAFTER_HOME/bin/crafter-deployer/config:
application.yaml: contains the global application properties, like the server port and the locations of other configuration files.
base-target.yaml: contains the common properties for all targets. In here you can find properties for configuring indexing with Crafter Search and deployment email notifications.
The application.yaml file is loaded automatically by Spring Boot, so its properties can be overridden in the standard external locations
defined by Spring Boot:
application.yamlin aconfigdirectory under the current directory.application.yamlin the current directory.application.yamlin aconfigdirectory in the classpath.application.yamlin the classpath root.
You can also override the application.yaml properties by specifying them as System properties, e.g. -Dserver.port=7171.
Here’s a sample application.yaml file (click on the triangle on the left to expand/collapse):
Sample application.yaml file
1deployer:
2 main:
3 config:
4 environment:
5 active: ${CRAFTER_ENVIRONMENT}
6 targets:
7 config:
8 folderPath: ${targets.dir}
9 deployments:
10 folderPath: ${deployments.dir}
11 output:
12 folderPath: ${logs.dir}
13 processedCommits:
14 folderPath: ${processedCommits.dir}
15 logging:
16 folderPath: ${logs.dir}
17 management:
18 # Deployer management authorization token
19 authorizationToken: ${DEPLOYER_MANAGEMENT_TOKEN}
20 security:
21 encryption:
22 # The key used for encryption of configuration properties
23 key: ${CRAFTER_ENCRYPTION_KEY}
24 # The salt used for encryption of configuration properties
25 salt: ${CRAFTER_ENCRYPTION_SALT}
26 ssh:
27 # The path of the folder used for the SSH configuration
28 config: ${CRAFTER_SSH_CONFIG}
The base-target.yaml file is handled a little bit differently. This file is loaded by Crafter Deployer every time a new target is added and is merged with the specific properties of the target,
with the target’s properties taking precedence. By default, the override location for this configuration file is CRAFTER_HOME/bin/crafter-deployer/config/base-target.yaml,
but it can be changed through the application.yaml property deployer.main.targets.config.baseYaml.overrideLocation.
Here’s a sample base-target.yaml file (click on the triangle on the left to expand/collapse):
Sample base-target.yaml file
1target:
2 localRepoPath: ${deployer.main.deployments.folderPath}/${target.siteName}
3 engineUrl: ${env:ENGINE_URL}
4 engineManagementToken: ${env:ENGINE_MANAGEMENT_TOKEN}
5 studioUrl: ${env:STUDIO_URL}
6 studioManagementToken: ${env:STUDIO_MANAGEMENT_TOKEN}
7 translation:
8 # Indicates if the translation features should be enabled for the target
9 enable: false
10 search:
11 openSearch:
12 # Single Cluster
13 urls:
14 - ${env:SEARCH_URL}
15 username: ${env:SEARCH_USERNAME}
16 password: ${env:SEARCH_PASSWORD}
17 timeout:
18 # The connection timeout in milliseconds, if set to -1 the default will be used
19 connect: -1
20 # The socket timeout in milliseconds, if set to -1 the default will be used
21 socket: -1
22 # The number of threads to use, if set to -1 the default will be used
23 threads: -1
24 # Indicates if keep alive should be enabled for sockets used by the search client, defaults to false
25 keepAlive: false
26
27 # Multiple Clusters
28 # readCluster:
29 # urls:
30 # username:
31 # password:
32 # writeClusters:
33 # - urls:
34 # username:
35 # password:
36 # - urls:
37 # username:
38 # password:
39
40 # Settings used for all indices
41 indexSettings:
42 - key: "index.mapping.total_fields.limit"
43 value : 3000
44 - key: "index.mapping.depth.limit"
45 value: 40
46
47 notifications:
48 mail:
49 server:
50 host: ${env:MAIL_HOST}
51 port: ${env:MAIL_PORT}
where:
engineURLandengineManagementToken``are required for calling Engine APIs, and the environment variables (*env:VARIABLE_NAME*) values are set in the ``crafter-setenv.shfile
studioURLandstudioManagementToken``are required for calling Studio APIs, and the environment variables (*env:VARIABLE_NAME*) values are set in the ``crafter-setenv.shfile
Target Configuration Files
Each deployment target has its own YAML configuration file, where the properties of the target and its entire deployment pipeline are specified.
Without this file, the Deployer doesn’t know of the target’s existence. By default, these configuration files reside under
./config/targets (in the case of the CrafterCMS installed on a server, they’re under CRAFTER_HOME/data/deployer/targets).
Target configurations vary a lot between authoring and delivery since an authoring target works on a local repository while a delivery target pulls the files from a remote repository. But target configurations between the same environment don’t change a lot. Having said that, the following two examples can be taken as a base for most authoring/delivery target configuration files:
1target:
2 # Environment name
3 env: preview
4 # Site name
5 siteName: editorial
6 # Crafter Engine base URL
7 engineUrl: http://localhost:8080
8 # Path to the sandbox repository of the site
9 localRepoPath: /opt/crafter/authoring/data/repos/sites/editorial/sandbox
10 deployment:
11 scheduling:
12 # Scheduling is disabled since Studio will call deploy on file save
13 enabled: false
14 pipeline:
15 # Calculates the Git differences with the latest commit processed
16 - processorName: gitDiffProcessor
17 # Performs Crafter Search indexing
18 - processorName: searchIndexingProcessor
19 # Calls Rebuild Context when a file under /scripts is changed
20 - processorName: httpMethodCallProcessor
21 includeFiles: ["^/?scripts/.*$"]
22 method: GET
23 url: ${target.engineUrl}/api/1/site/context/rebuild.json?crafterSite=${target.siteName}
24 # Calls Clear Cache
25 - processorName: httpMethodCallProcessor
26 method: GET
27 url: ${target.engineUrl}/api/1/site/cache/clear.json?crafterSite=${target.siteName}
28 # Generates a deployment output file
29 - processorName: fileOutputProcessor
1target:
2 # Environment name
3 env: dev
4 # Site name
5 siteName: editorial
6 # Crafter Engine base URL
7 engineUrl: http://localhost:9080
8 deployment:
9 pipeline:
10 # Pulls the remote Git repository of the site
11 - processorName: gitPullProcessor
12 remoteRepo:
13 # URL of the remote repo
14 url: /opt/crafter/authoring/data/repos/sites/editorial/published
15 # Live of the repo to pull
16 branch: live
17 # Calculates the Git differences with the latest commit processed
18 - processorName: gitDiffProcessor
19 # Performs Crafter Search indexing
20 - processorName: searchIndexingProcessor
21 # Calls Rebuild Context when a file under /scripts is changed
22 - processorName: httpMethodCallProcessor
23 includeFiles: ["^/?scripts/.*$"]
24 method: GET
25 url: ${target.engineUrl}/api/1/site/context/rebuild.json?crafterSite=${target.siteName}
26 # Calls Clear Cache
27 - processorName: httpMethodCallProcessor
28 method: GET
29 url: ${target.engineUrl}/api/1/site/cache/clear.json?crafterSite=${target.siteName}
30 # Generates a deployment output file
31 - processorName: fileOutputProcessor
As you can see from the examples above, most of the configuration belongs to the deployment pipeline section. Each
of the YAML list entries is an instance of a DeploymentProcessor prototype Spring bean that is already defined
in the base-context.xml file. If you want to define your own set of DeploymentProcessor beans you can add
them on a new Spring context file based on the target’s YAML file name. Using the authoring example above, since
the YAML file name is editorial-preview.yaml, the corresponding Spring context would be editorial-preview-context.xml.
The Deployer out of the box provides the following processor beans:
gitPullProcessor: Clones a remote repository into a local path. If the repository has been cloned already, it performs a Git pull. This is useful for delivery targets which need to reach out to the authoring server to retrieve the changes on deployment. This must be the first processor in the list since the rest of the processors work on the local repository.
gitDiffProcessor: Calculates the diff between the latest commit in the local repository and the last commit processed, which is usually stored under
./processed-commits(in the folderCRAFTER_HOME/data/deployer/processed-commits). This diff is then used to build the change set of the deployment, so this processor should be the second on the list.searchIndexingProcessor: grabs the files from the change set and sends them to Crafter Search for indexing. It also does some XML processing before submitting the files like flattening (recursive inclusion of components), merging of inherited XML and metadata extraction for structured document files like PDFs, Word Docs, etc.
httpMethodCallProcessor: executes an HTTP method call to a specified URL.
fileOutputProcessor: generates the deployment output and saves it to a CSV file.
mailNotificationProcessor: sends an email notification when there’s a successful deployment with file changes or when a deployment failed.
Deployer Configuration Properties
In this section, we will highlight some of the more commonly used properties in the configuration of Crafter Deployer.
Property |
Purpose |
|---|---|
Allows you to configure the deployment pool |
The properties listed above are configured in CRAFTER_HOME/bin/crafter-deployer/config/application.yaml.
Property |
Purpose |
|---|---|
Allows you to configure a target with a single search cluster |
|
Allows you to configure a target with multiple search clusters |
|
Allows you to configure MIME types used for document indexing |
|
Allows you to configure remote documents path patterns used for document indexing |
|
Allows you to configure metadata path patterns used for document indexing |
The target properties listed above may be configured in the following locations:
Global configuration file
$CRAFTER_HOME/bin/crafter-deployer/config/base-target.yamlIndividual target configuration file
$CRAFTER_HOME/data/deployer/targets/{siteName}-{environment}.yaml
Single Search Cluster
The following allows you to configure a target with a single search cluster. This is the most common configuration used, all operations will be performed on a single search cluster:
1 target:
2 search:
3 openSearch:
4 # Single cluster
5 urls:
6 - ${env:SEARCH_URL}
7 username: ${env:SEARCH_USERNAME}
8 password: ${env:SEARCH_PASSWORD}
9 timeout:
10 # The connection timeout in milliseconds, if set to -1 the default will be used
11 connect: -1
12 # The socket timeout in milliseconds, if set to -1 the default will be used
13 socket: -1
14 # The number of threads to use, if set to -1 the default will be used
15 threads: -1
16 # Indicates if keep alive should be enabled for sockets used by the search client, defaults to false
17 keepAlive: false
Multiple Search Engines or Search Engine Clusters
There may be cases where an enterprise needs to run multiple search engines or search engine clusters that carry the same data for extra redundancy beyond regular clustering. The following allows you to configure a target with multiple search clusters. In the configuration below, all read operations will be performed against one search cluster but write operations will be performed against all search clusters:
1 target:
2 search:
3 openSearch:
4 # Global auth, used for all clusters
5 username: search
6 password: passw0rd
7 # Cluster for read operations
8 readCluster:
9 urls:
10 - 'http://read-cluster-node-1:9200'
11 - 'http://read-cluster-node-2:9200'
12 # This cluster will use the global auth
13 # Clusters for write operations
14 writeClusters:
15 - urls:
16 - 'http://write-cluster-1-node-1:9200'
17 - 'http://write-cluster-1-node-2:9200'
18 # This cluster will use the global auth
19 - urls:
20 - 'http://write-cluster-2-node-1:9200'
21 - 'http://write-cluster-2-node-2:9200'
22 # Override the global auth for this cluster
23 username: search2
24 password: passw0rd2
MIME types
The supportedMimeTypes configured in the base-target.yaml file determines what MIME types are used for indexing.
The following is the default list of MIME types with full-text-search indexing enabled.
1target:
2...
3 search:
4 openSearch:
5 ...
6 binary:
7 # The list of binary file mime types that should be indexed
8 supportedMimeTypes:
9 - application/pdf
10 - application/msword
11 - application/vnd.openxmlformats-officedocument.wordprocessingml.document
12 - application/vnd.ms-excel
13 - application/vnd.ms-powerpoint
14 - application/vnd.openxmlformats-officedocument.presentationml.presentation
To add other MIME types to the list of MIME types with full-text-search indexing enabled, simply edit the override file
CRAFTER_HOME/bin/crafter-deployer/config/base-target.yaml and add to the list.
Say we want to add bitmaps to the supported MIME types, we’ll add the MIME type image/bmp to the list above under
target.search.binary.supportedMimeTypes:
1target:
2...
3 search:
4 openSearch:
5 ...
6 binary:
7 # The list of binary file mime types that should be indexed
8 supportedMimeTypes:
9 - image/bmp
For a list of common MIME types, see https://developer.mozilla.org/en-US/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Common_types.
Remote Documents Path Pattern
CrafterCMS can index documents that reside in remote repositories, but are pointed-to by CrafterCMS content.
The remoteBinaryPathPatterns configured in the base-target.yaml file determines what a remote document
is, within a content item, via the regex path pattern. The default for this is configured as follows:
1target:
2...
3 search:
4 openSearch:
5 ...
6 binary:
7 ...
8 # The regex path patterns for binary/document files that are stored remotely
9 remoteBinaryPathPatterns: &remoteBinaryPathPatterns
10 # HTTP/HTTPS URLs are only indexed if they contain the protocol (http:// or https://). Protocol relative
11 # URLs (like //mydoc.pdf) are not supported since the protocol is unknown to the back-end indexer.
12 - ^(http:|https:)//.+$
13 - ^/remote-assets/.+$
To add other remote document path patterns to the list, simply edit the override file
CRAFTER_HOME/bin/crafter-deployer/config/base-target.yaml and add to the list under
target.search.binary.remoteBinaryPathPatterns.
Metadata Path Pattern
The metadataPathPatterns configured in the base-target.yaml file determines if a document should be indexed with
the metadata of the object that points to it (a so-called “jacket”). The deployer will re-index the jacket and the
document together whenever the jacket is updated. See Jacket for more information.
1target:
2...
3 search:
4 openSearch:
5 ...
6 binary:
7 ...
8 # The regex path patterns for the metadata ("jacket") files of binary/document files
9 metadataPathPatterns:
10 - ^/?site/documents/.+\.xml$
To add other jacket patterns to the list, simply edit the override file
CRAFTER_HOME/bin/crafter-deployer/config/base-target.yaml and add to the list under
target.search.binary.metadataPathPatterns.
Thread Pool Size
As the number of sites grows you may need more workers (threads) in the Deployer to service them. If you do not add more workers then you will see errors in scheduled tasks. Eventually, the system will get through the workload with the workers it has available, and the error will stop, but the presence of these errors on a regular basis indicates that you need more workers in the pool.
There are two thread pools available. The deployment pool, which is used to run all deployments and the task scheduler pool, which is used for starting deployments on a schedule of every 10 secs. For deployments of sites with a lot content (big sites), we recommend increasing the deployment pool. For deployments with a lot of sites, we recommend increasing the task scheduler pool.
To increase the deployment pool, set the following items in CRAFTER_HOME/bin/crafter-deployer/config/application.yaml
as shown below:
1deployer:
2 main:
3 deployments:
4 pool:
5 # Thread pool core size
6 size: 25
7 # Thread pool max size
8 max: 100
9 # Thread pool queue size
10 queue: 100
To increase the thread pool size of the task scheduler, set the poolSize property in
CRAFTER_HOME/bin/crafter-deployer/config/application.yaml as shown below:
1deployer:
2 main:
3 taskScheduler:
4 # Thread pool size of the task scheduler
5 poolSize: 20
Here’s a sample application.yaml file with the deployment pool and task thread pool configured:
Sample application.yaml file showing Deployment and Task Scheduler Pools
1deployer:
2 main:
3 taskScheduler:
4 # Thread pool size of the task scheduler
5 poolSize: 20
6 config:
7 environment:
8 active: ${CRAFTER_ENVIRONMENT}
9 targets:
10 config:
11 folderPath: ${targets.dir}
12 deployments:
13 pool:
14 # Thread pool core size
15 size: 25
16 # Thread pool max size
17 max: 100
18 # Thread pool queue size
19 queue: 100
20 folderPath: ${deployments.dir}
21 output:
22 folderPath: ${logs.dir}
23 processedCommits:
24 folderPath: ${processedCommits.dir}
25 logging:
26 folderPath: ${logs.dir}
27 management:
28 # Deployer management authorization token
29 authorizationToken: ${DEPLOYER_MANAGEMENT_TOKEN}
30 security:
31 encryption:
32 # The key used for encryption of configuration properties
33 key: ${CRAFTER_ENCRYPTION_KEY}
34 # The salt used for encryption of configuration properties
35 salt: ${CRAFTER_ENCRYPTION_SALT}
36 ssh:
37 # The path of the folder used for the SSH configuration
38 config: ${CRAFTER_SSH_CONFIG}
Administration
How to Start/Stop the Deployer
If you’re using CrafterCMS installed on a server, starting and stopping the Deployer is very easy. From the command line, navigate to the
{env-directory}, authoring or delivery environment folder, and then inside the bin folder, run ./crafter.sh start_deployer to start
the Deployer or ./crafter.sh stop_deployer to stop the Deployer.
Manage Targets
Create a Target
There are two different ways in which a target configuration file can be created:
By calling the API endpoint createTarget, which creates a new target based on a template. The Deployer comes out of the box with two templates: one for local repositories (useful for authoring environments) and one for remote repositories (useful for delivery environments). You can also specify your templates under
./config/templates/targets, and use the same API endpoint to create targets based on those templates.By placing the YAML target configuration file under
./config/targets(orCRAFTER_HOME/data/deployer/targets, like indicated above). The Deployer will automatically load the file on a schedule, and whenever there’s a change it will re-load it.
Update a Target
Updating a target is very similar to creating one:
Call the same API endpoint as create, but be sure that the
replaceparameter istrue. ORMake the changes directly in the target configuration file. On the next scheduled scan of targets, the Deployer will detect that the file has been modified and it will re-load it.
Delete a Target
There are two options for deleting a target:
Call the API endpoint deleteTarget.
Delete the target configuration file in the filesystem.
Target Templates
When you are creating a target in Crafter Deployer, you can use one of the included templates that can be easily customized with additional parameters during the creation.
Built-in Templates
All target templates support the following parameters:
Name |
Required |
Description |
|---|---|---|
|
✓ |
The target’s environment (e.g. dev) |
|
✓ |
The target’s site name (e.g. mysite) |
|
✓ |
The target’s repository URL |
Local Target
This is the other template used by Crafter Studio when a new project is created, this template will create a target for previewing the project.
This target will:
Identify the changed files according to the local Git repository history
Index all project content in the search index
Rebuild Crafter Engine’s site context when there are changes in the configuration files or Groovy scripts
Clear Crafter Engine’s cache
Rebuild Crafter Engine’s project GraphQL schema when there are changes in the content-type definitions
Send email notifications if enabled
Parameters
Name |
Required |
Description |
|---|---|---|
|
Disables the cron job that runs deployments every certain amount of time |
|
|
The email addresses that should receive deployment notifications |
Note
When this target is used, the value of repo_url must be a local filesystem path
Remote Target
This is the default template used for Crafter Engine in delivery environments, it is very similar to the Local Target but it adds support for remote Git repositories.
This target will:
Clone the remote repository if needed
Pull the latest changes from the remote repository (discarding any local uncommitted or conflicting files)
Identify the changed files according to the Git repository history
Index all project content in the appropriate search engine
Rebuild Crafter Engine’s site context when there are changes in the configuration files or Groovy scripts
Clear Crafter Engine’s cache
Rebuild Crafter Engine’s project GraphQL schema when there are changes in the content-type definitions
Send email notifications if enabled
Parameters
Name |
Required |
Description |
|---|---|---|
|
Disables the cron job that runs deployments every certain amount of time |
|
|
The branch name of the remote Git repo to pull from |
|
|
Username to access remote repository |
|
|
Password to access remote repository |
|
|
The path for the private key to access the remote repository |
|
|
The passphrase for the private key to access the remote repository (only if the key is passphrase-protected) |
|
|
The email addresses that should receive deployment notifications |
Note
When this target is used, the value of repo_url must be a supported Git URL (HTTP/S or SSH)
AWS S3 Target
This template is used for Crafter Engine in serverless delivery environments, it is very similar to the Remote Target but it adds support for syncing files to an AWS S3 bucket and handles AWS Cloudfront invalidations.
This target will:
Clone the remote repository if needed
Pull the latest changes from the remote repository (discarding any local uncommitted or conflicting files)
Identify the changed files according to the Git repository history
Index all project content in the search index
Sync all new, updated, and deleted files to an AWS S3 bucket
Execute an invalidation for all updated files in one or more AWS Cloudfront distributions
Submit deployments events for all Crafter Engine instances:
Rebuild the site context when there are changes in the configuration files or Groovy scripts
Clear Crafter Engine’s cache
Rebuild the site GraphQL schema when there are changes in the content-type definitions
Send email notifications if enabled
Parameters
Name |
Required |
Description |
|---|---|---|
|
The AWS Region to use |
|
|
The AWS Access Key to use |
|
|
The AWS Secret Key to use |
|
|
An array of AWS Cloudfront distribution ids to execute invalidations |
|
|
✓ |
The full AWS S3 URI of the folder to sync files |
|
Disables the cron job that runs deployments every certain amount of time |
|
|
The local path where to put the remote Git repo clone |
|
|
The branch name of the remote Git repo to pull from |
|
|
Username to access remote repository |
|
|
Password to access remote repository |
|
|
The path for the private key to access the remote repository |
|
|
The passphrase for the private key to access the remote repository (only if the key is passphrase-protected) |
|
|
The email addresses that should receive deployment notifications |
Note
When this target is used, the value of repo_url must be a supported Git URL (HTTP/S or SSH)
Note
For more details about setting up a serverless delivery see Serverless Delivery
AWS CloudFormation Target
This template is used to provide a serverless delivery environment without the need to manually create all required resources in AWS. It works similarly to the AWS S3 Target but uses an AWS CloudFormation template to create the AWS resources on target creation: the S3 bucket where the site content will be stored and a CloudFront distribution that will front an Engine load balancer and deliver the static assets directly from the S3 bucket. These resources will be deleted when the target is deleted.
This target will:
Clone the remote repository if needed
Pull the latest changes from the remote repository (discarding any local uncommitted or conflicting files)
Identify the changed files according to the Git repository history
Index all project content in the search index
Sync all new, updated, and deleted files to an AWS S3 bucket
Execute an invalidation for all updated files in the AWS CloudFront distribution
Submit deployments events for all Crafter Engine instances:
Rebuild the site context when there are changes in the configuration files or Groovy scripts
Clear Crafter Engine’s cache
Rebuild the site GraphQL schema when there are changes in the content-type definitions
Send email notifications if enabled
Parameters
Name |
Required |
Description |
|---|---|---|
|
The AWS Region to use |
|
|
The AWS Access Key to use for S3 and CloudFront |
|
|
The AWS Secret Key to use for S3 and CloudFront |
|
|
✓ |
Prefix to use for CloudFormation resource names |
|
✓ |
The domain name of the Engine delivery LB |
|
The ARN of the CloudFront SSL certificate |
|
|
The alternate domain names for the CloudFront to use (must match the valid certificate domain names) |
|
|
The AWS Access Key to use for CloudFormation |
|
|
The AWS Secret Key to use for CloudFormation |
|
|
Disables the cron job that runs deployments every certain amount of time |
|
|
The local path where to put the remote Git repo clone |
|
|
The branch name of the remote Git repo to pull from |
|
|
Username to access remote repository |
|
|
Password to access remote repository |
|
|
The path for the private key to access remote repository |
|
|
The passphrase for the private key to access the remote repository (only if the key is passphrase-protected) |
|
|
The email addresses that should receive deployment notifications |
Note
When this target is used, the value of repo_url must be a supported Git URL (HTTP/S or SSH)
Run Deployments
Crafter Deployer has an option of running scheduled deployments for a target (deployment.scheduling.enabled), which is enabled by default, but if you
want to manually trigger a deployment, you just need to call the API endpoint deployTarget (or
deployAllTargets). This will start the deployment if the request is correct. To watch the progress of a scheduled or manually
triggered deployment, check the Deployer log. When the deployment has finished, and the target has a fileOutputProcessor in the deployment pipeline, a
CSV file with the final result of that particular deployment will be written under ./logs (or CRAFTER_HOME/logs/deployer).
Processed Commits
Crafter Deployer keeps track of the most recent commit ID that was processed in the last deployment
for each target, during a deployment, it will use this commit ID to get the list of files that have been
changed in the repository.
By default, the processed commits are stored in a folder (CRAFTER_HOME/data/deployer/processed-commits)
as an individual file for each target (for example editorial-preview.commit). Each file contains
only the commit ID will be used to track the changes during deployments:
10be0d2e52283c17b834901e9cda6332d06fb05b6
If the repository is changed manually using Git commands instead of updating files using Crafter Studio it is possible that a deployment may find a conflict, for example, if a specific commit is deleted from the repository. In most cases, Crafter Deployer should be able to detect those conflicts and solve them automatically, however, if a deployment does not finish successfully you can follow the steps described in Troubleshooting Deployer Issues
Warning
Changing or deleting a processed commit file could cause unchanged files to be indexed again and it should be done as a last resort in case of errors.
Jacket
Jackets are CrafterCMS content items that carry metadata about a binary file. Jackets _wrap_ a binary file and augment it with metadata that flows into the search index as a single document. This makes for a much richer and more effective search experience. Jackets are modeled as a content item like any other content item and can carry arbitrary fields.
Crafter Deployer can index the content of a binary document if it can be transformed to text or has textual metadata. For example, PDF files, Office files, etc. will be indexed and made full-text-searchable. When jacketed, these files will be indexed along with the metadata provided by the jacket.
Jackets are identified by their path and a regex that is configured at the Deployer configuration’s target level.
Administrators must configure where jackets are located via the base-target.yaml configuration file found in
CRAFTER_HOME/bin/crafter-deployer/config/. Jacket files live under /site/documents by default.
An example of a how a jacket is resolved is to have a binary file /static-assets/documents/contracts/2024-contract.pdf, and the Deployer
resolves its jacket at /site/documents/contracts/2024-contract.xml, extracts the XML content of the jacket,
and indexes everything under /static-assets/documents/contracts/2024-contract.pdf
Below is an example Deployer configuration for jackets. Note that in the example below, jacket files live under /site/documents:
1target:
2...
3 search:
4 openSearch:
5 ...
6 binary:
7 # The list of binary file mime types that should be indexed
8 supportedMimeTypes:
9 - application/pdf
10 - application/msword
11 - application/vnd.openxmlformats-officedocument.wordprocessingml.document
12 - application/vnd.ms-excel
13 - application/vnd.ms-powerpoint
14 - application/vnd.openxmlformats-officedocument.presentationml.presentation
15 # The regex path patterns for the metadata ("jacket") files of binary/document files
16 metadataPathPatterns:
17 - ^/?site/documents/.+\.xml$
18 # The regex path patterns for binary/document files that are stored remotely
19 remoteBinaryPathPatterns: &remoteBinaryPathPatterns
20 # HTTP/HTTPS URLs are only indexed if they contain the protocol (http:// or https://). Protocol relative
21 # URLs (like //mydoc.pdf) are not supported since the protocol is unknown to the back-end indexer.
22 - ^(http:|https:)//.+$
23 - ^/remote-assets/.+$
24 # The regex path patterns for binary/document files that should be associated to just one metadata file and are
25 # dependant on that parent metadata file, so if the parent is deleted the binary should be deleted from the index
26 childBinaryPathPatterns: *remoteBinaryPathPatterns
27 # The XPaths of the binary references in the metadata files
28 referenceXPaths:
29 - //item/key
30 - //item/url
31 # Setting specific for authoring indexes
32 authoring:
33 # Xpath for the internal name field
34 internalName:
35 xpath: '*/internal-name'
36 includePatterns:
37 - ^/?site/.+$
38 - ^/?static-assets/.+$
39 - ^/?remote-assets/.+$
40 - ^/?scripts/.+$
41 - ^/?templates/.+$
42 contentType:
43 xpath: '*/content-type'
44 # Same as for delivery but include images and videos
45 supportedMimeTypes:
46 - application/pdf
47 - application/msword
48 - application/vnd.openxmlformats-officedocument.wordprocessingml.document
49 - application/vnd.ms-excel
50 - application/vnd.ms-powerpoint
51 - application/vnd.openxmlformats-officedocument.presentationml.presentation
52 - application/x-subrip
53 - image/*
54 - video/*
55 - audio/*
56 - text/x-freemarker
57 - text/x-groovy
58 - text/javascript
59 - text/css
60 # The regex path patterns for the metadata ("jacket") files of binary/document files
61 metadataPathPatterns:
62 - ^/?site/documents/.+\.xml$
63 binaryPathPatterns:
64 - ^/?static-assets/.+$
65 - ^/?remote-assets/.+$
66 - ^/?scripts/.+$
67 - ^/?templates/.+$
68 # Look into all XML descriptors to index all binary files referenced
69 binarySearchablePathPatterns:
70 - ^/?site/.+\.xml$
71 # Additional metadata such as contentLength, content-type specific metadata
72 metadataExtractorPathPatterns:
73 - ^/?site/.+$
74 excludePathPatterns:
75 - ^/?config/.*$
76 # Include all fields marked as remote resources (S3, Box, CMIS)
77 referenceXPaths:
78 - //item/key
79 - //item/url
80 - //*[@remote="true"]
Example
Let’s take a look at an example of setting up jackets for binary content. We’ll use a project created using the Website Editorial blueprint, and do the following:
Create a directory for binary content
static-assets/documents, and the directory for storing the jackets/site/documents/in your projectConfigure the Sidebar cabinet for the new content type created in a previous step and set up permissions for roles interacting with the documents
Create content model for jackets and configure the project for the new content model
Let’s begin setting up a jacket for binary contents.
First, we’ll create the directory that will contain the binary content, static-assets/documents via Studio. On the
Sidebar, scroll down to static-assets, then click on the more menu (the three dots) and select New Folder and type in
Documents for the Folder Name.
Next, we’ll create the directory for storing the jackets in the project /site/documents/ using your favorite
terminal program, add a .keep file inside the directory and finally add and commit it.
cd CRAFTER_HOME/data/repos/sites/SITENAME/sandbox
mkdir site/documents
touch site/documents/.keep
git add site/documents/.keep
git commit -m "Add documents folder"
The next step is to set up the Sidebar cabinet for our jackets in Studio. To add the cabinet, open the
User Interface Configuration file by opening the Sidebar in Studio, then clicking on Project Tools -> Configuration
-> User Interface Configuration. Scroll down to the ToolsPanel widget, and add a Documents widget under the
Pages widget like below:
<widget id="craftercms.components.ToolsPanel">
<configuration>
<widgets>
...
<widget id="craftercms.components.PathNavigatorTree">
<configuration>
<id>Pages</id>
...
<widget id="craftercms.components.PathNavigatorTree">
<configuration>
<id>Documents</id>
<label>Documents</label>
<icon id="@mui/icons-material/DescriptionOutlined"/>
<rootPath>/site/documents</rootPath>
<locale>en</locale>
</configuration>
</widget>
...
We’ll now set up permissions for roles interacting with the documents. For our example, we’ll add permissions for
the author role. Open the Permissions Mapping file by opening the Sidebar in Studio, then clicking on
Project Tools -> Configuration -> Permissions Mapping. Scroll down to the <role name="author"> section,
and add a regex for our /site/documents folder we created like below:
<permissions>
<version>4.1.2</version>
<role name="author">
<rule regex="/site/website/.*">
<allowed-permissions>
...
<rule regex="/site/documents|/site/documents/.*">
<allowed-permissions>
<permission>content_read</permission>
<permission>content_write</permission>
<permission>content_create</permission>
<permission>folder_create</permission>
<permission>get_children</permission>
<permission>content_copy</permission>
</allowed-permissions>
</rule>
...
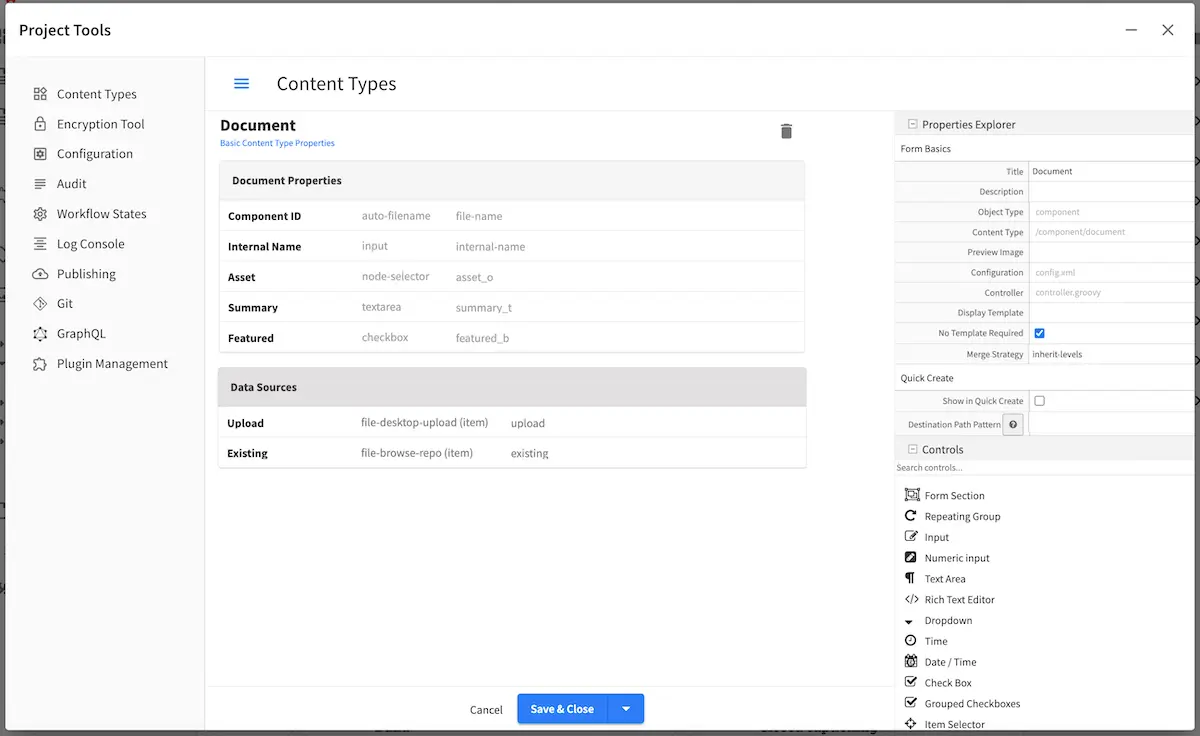
Next, we’ll create the content model for your jacket. To create a new content type, open the Content Types tool by
opening the Sidebar in Studio, then clicking on Project Tools -> Content Types. Click on the Create New Type
button, and use Document for the label and ID, and select Component for Type, then finally, click
on the Create button.
For the content type, we will add an Item Selector control that we’ll name Asset, and
a couple of data sources that will be bound to the control. We will use the /static-assets/documents folder we
created earlier for the Repository Path of the two data sources we’ll be adding, a File Upload From Desktop data
source that we’ll name Upload and a File Browse data source that we’ll name Existing. For the metadata in
the jacket, it is up to you on what you’d like in the content model. For our example, we will add a Text Area control
named Summary, and a Check Box control named Featured.
Finally, we’ll set up our project for the content model we just created. Open the Project Configuration file by
opening the Sidebar in Studio, then clicking on Project Tools -> Configuration -> Project Configuration.
Scroll down to the <repository rootPrefix="/site"> section and add the folder /site/documents we created to the
folders section. Next, scroll down to the <patterns> section. We’ll add /site/documents to the component group.
<repository rootPrefix="/site">
...
<folders>
<folder name="Pages" path="/website" read-direct-children="false" attach-root-prefix="true"/>
<folder name="Components" path="/components" read-direct-children="false" attach-root-prefix="true"/>
<folder name="Documents" path="/documents" read-direct-children="false" attach-root-prefix="false"/>
<folder name="Taxonomy" path="/taxonomy" read-direct-children="false" attach-root-prefix="true"/>
...
</folders>
<!-- Item Patterns -->
<patterns>
...
<pattern-group name="component">
<pattern>/site/components/([^<]+)\.xml</pattern>
<pattern>/site/documents/([^<]+)\.xml</pattern>
<pattern>/site/system/page-components/([^<]+)\.xml</pattern>
...
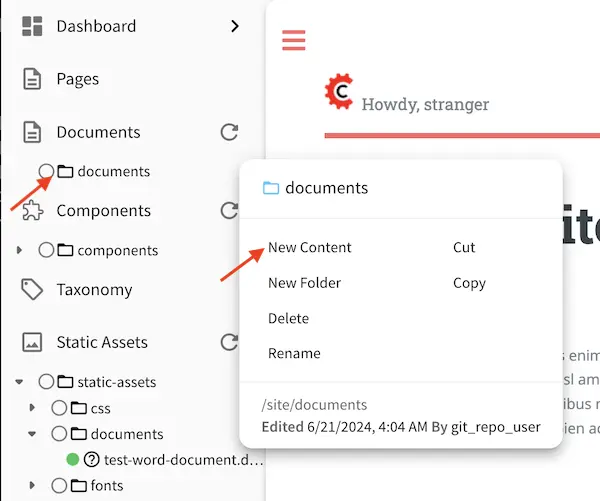
Our content model for the jacket is now complete! To add a jacket to content uploaded in static-assets/documents,
open the Sidebar and scroll to Documents. Open the cabinet then click on the three dots next to documents, then
select New Content.
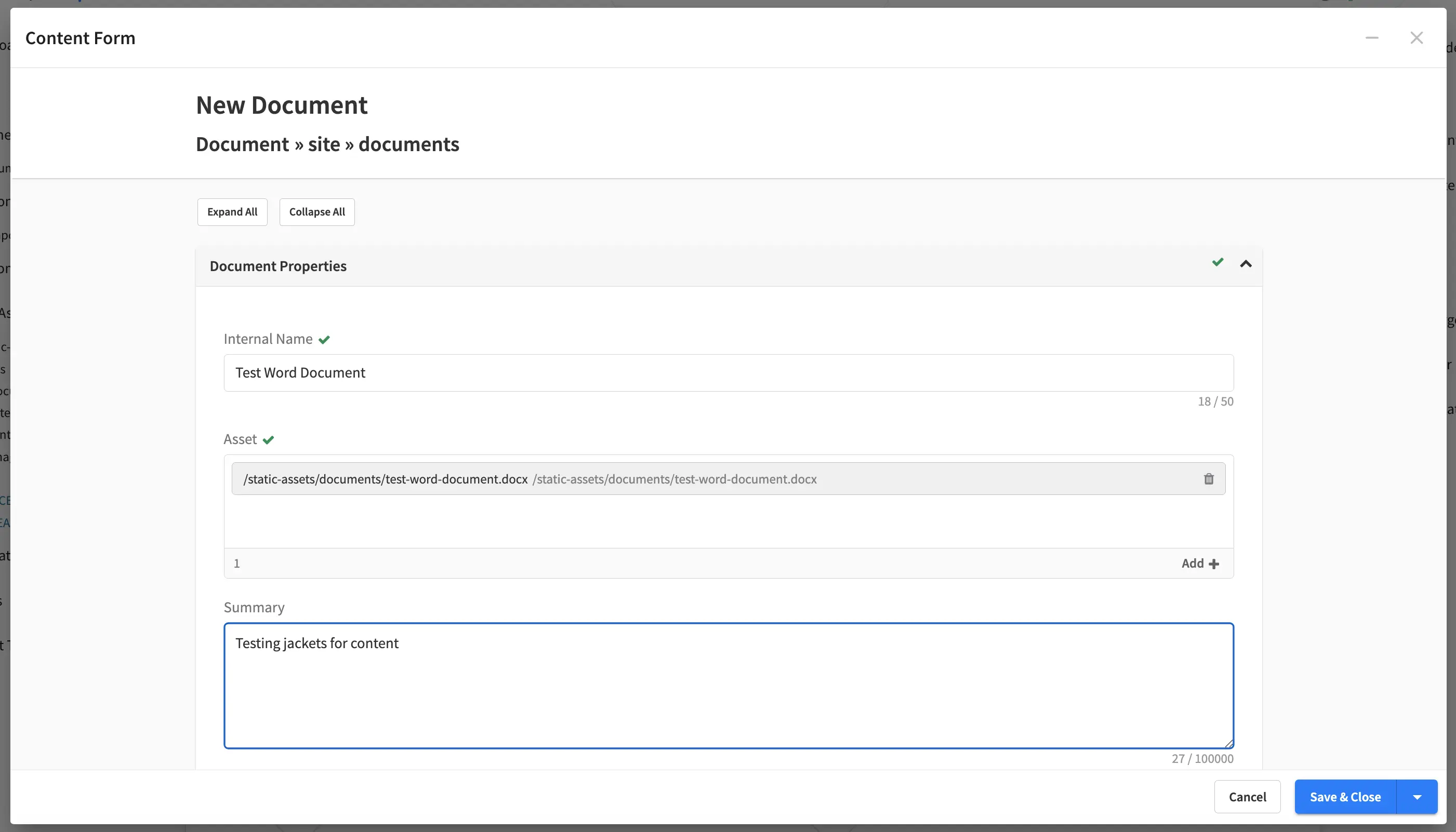
Fill in the fields on the form and save.
Publish the changes. The binary content and jacket will now be indexed under the location of the binary content.
Deployer Processors
Crafter Deployer includes an extensive list of deployment processors that can be easily added to any target to meet specific requirements. Some examples of the use cases that can be addressed with deployment processors are:
Pushing content created/edited in Crafter Studio to an external git repository
Pulling content created/edited from an external git repository
Execute actions every time a deployment succeeds or fails
Note
When adding processors or changing the deployment pipeline for a target keep in mind that the processors will be executed following the order defined in the configuration file and some processors require a specific position in the pipeline
Main Deployment Processors
The main deployment processors can do any task related to detecting a change-set (changed files) or processing a change-set (changed files) that were detected by other processors. To process a change-set, a processor may interact with any external service as needed.
All deployment processors support the following properties:
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
None |
Label that other processors can use to jump to this one |
|
|
None |
The label of the processor to jump to after a successful execution |
|
|
None |
List of regular expressions to check the files that should be included |
|
|
None |
List of regular expressions to check the files that should be excluded |
|
|
false |
Indicates if the processor should run even if there are no changes in the current deployment |
|
|
false |
Enables failing a deployment when there’s a processor failure |
|
|
|
Indicates the current ClusterMode the processor should run. Available values are:
The default value
|
Git Pull Processor
Processor that clones/pulls a remote Git repository into a local path on the filesystem.
Note
This needs to be the first processor in the pipeline
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
✓ |
The URL of the remote Git repo to pull |
|
|
|
The name to use for the remote repo when pulling from it |
|
|
The default branch in the repo |
The branch of the remote Git repo to pull |
|
|
The username for authentication with the remote Git repo. Not needed when SSH with RSA key pair authentication is used |
||
|
The password for authentication with the remote Git repo. Not needed when SSH with RSA key pair authentication is used |
||
|
The SSH private key path, used only with SSH with RSA key pair authentication |
||
|
The SSH private key passphrase, used only with SSH withRSA key pair authentication |
||
|
|
Enables failing a deployment when there’s a processor failure |
Example
1- processorName: gitPullProcessor
2 remoteRepo:
3 url: https://github.com/myuser/mysite.git
4 branch: live
5 username: myuser
6 password: mypassword
1- processorName: gitPullProcessor
2 remoteRepo:
3 url: https://github.com/myuser/mysite.git
4 branch: live
5 ssh:
6 privateKey:
7 path: /home/myuser/myprivatekey
8 passphrase: mypassphrase
Git Diff Processor
Processor that, based on a previously processed commit that’s stored, does a diff with the current commit of the deployment, to find out the change-set. If there is no previously processed commit, then the entire repository becomes the change-set.
Note
This processor needs to be placed after the gitPullProcessor and before any other processor like the
searchIndexingProcessor
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
|
Indicates if the git log details should be included in the change set |
|
|
|
Indicates if the processed commit value should be modified |
|
|
|
Enables failing a deployment when there’s a processor failure |
Example
1- processorName: gitDiffProcessor
2 includeGitLog: true
Git Push Processor
Processor that pushes a local repo to a remote Git repository.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
✓ |
The branch of the local repo to push |
|
|
✓ |
The URL of the remote Git repo to push to |
|
|
The default branch in the repo |
The branch of the remote Git repo to push to |
|
|
The username for authentication with the remote Git repo. Not needed when SSH with RSA key pair authentication is used |
||
|
The password for authentication with the remote Git repo. Not needed when SSH with RSA key pair authentication is used |
||
|
The SSH private key path, used only with SSH with RSA key pair authentication |
||
|
The SSH private key passphrase, used only with SSH withRSA key pair authentication |
||
|
|
Sets the force preference for the push |
|
|
|
If all local branches should be pushed to the remote |
Example
1- processorName: gitPushProcessor
2 remoteRepo:
3 url: https://github.com/myuser/mysite.git
4 branch: deployed
5 username: myuser
6 password: mypassword
1- processorName: gitPushProcessor
2 remoteRepo:
3 url: https://github.com/myuser/mysite.git
4 branch: deployed
5 ssh:
6 privateKey:
7 path: /home/myuser/myprivatekey
8 passphrase: mypassphrase
Git Update Commit Id Processor
Processor that updates the processed commits value with the current commit.
Example
1- processorName: gitUpdateCommitIdProcessor
Groovy Script Processor
A custom Groovy processor that can process published content.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
scriptPath |
✓ |
The relative path of the script to execute |
Note
The default path scripts are loaded from is
$CRAFTER_HOME/bin/crafter-deployer/processors/scripts
Example
1- processorName: scriptProcessor
2 scriptPath: 'myscripts/mychanges.groovy'
The following variables are available for use in your scripts:
Variable Name |
Description |
|---|---|
logger |
The processor’s logger, http://www.slf4j.org/api/org/slf4j/Logger.html |
applicationContext |
The application context of the current target, https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/context/ApplicationContext.html |
deployment |
The current deployment, http://javadoc.craftercms.org/4.1.8/deployer/org/craftercms/deployer/api/Deployment.html |
execution |
The execution for this processor, http://javadoc.craftercms.org/4.1.8/deployer/org/craftercms/deployer/api/ProcessorExecution.html |
filteredChangeSet |
A subset of |
originalChangeSet |
The original change set returned by the previous processors in the pipeline, http://javadoc.craftercms.org/4.1.8/deployer/org/craftercms/deployer/api/ChangeSet.html |
Let’s take a look at an example script that you can use for the Groovy script processor. Below is a script that only includes a file from the change-set if a parameter is present in the deployment:
1import org.craftercms.deployer.api.ChangeSet
2
3logger.info("starting script execution")
4
5def specialFile = "/site/website/expensive-page-to-index.xml"
6
7// if the file has been changed but the param was not sent then remove it from the change set
8if (originalChangeSet.getUpdatedFiles().contains(specialFile) && !deployment.getParam("index_expensive_page")) {
9 originalChangeSet.removeUpdatedFile(specialFile)
10}
11
12// return the new change set
13return originalChangeSet
File Based Deployment Event Processor
Processor that triggers a deployment event that consumers of the repository (Crafter Engine instances) can subscribe to by reading a specific file from the repository.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
|
Relative path of the deployment events file |
|
|
✓ |
Name of the event to trigger |
Example
1- processorName: fileBasedDeploymentEventProcessor
2 eventName: 'events.deployment.rebuildContext'
Command Line Processor
Processor that runs a command line process (e.g. a shell script).
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
Deployer’s directory |
The directory from which the process will run |
|
|
✓ |
The full command that the process will run |
|
|
|
The amount of seconds to wait for the process to finish |
|
|
|
Additional parameters will be added to the command Example: script.sh SITE_NAME OPERATION (CREATE | UPDATE | DELETE) FILE (relative path of the file) |
Example
1- processorName: commandLineProcessor
2 workingDir: '/home/myuser/myapp/bin'
3 command: 'myapp -f --param1=value1'
Search Indexing Processor
Processor that indexes the files on the change-set, using one or several BatchIndexer. After the files have been indexed it submits a commit.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
|
If the index ID should be ignored |
|
|
Value of |
The specific index ID to use |
|
|
|
Flag that indicates that if a component is updated, all other pages and components that include it should be updated too |
Example
1- processorName: searchIndexingProcessor
HTTP Method Call Processor
Processor that does a HTTP method call.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
✓ |
The URL to call |
|
|
✓ |
The HTTP method |
Example
1- processorName: httpMethodCallProcessor
2 method: GET
3 url: 'http://localhost:8080/api/1/site/cache/clear.json?crafterSite=mysite'
Delay Processor
Processor that pauses the pipeline execution for a given number of seconds.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
|
Amount of seconds to wait |
Example
1- processorName: delayProcessor
2 seconds: 10
Find And Replace Processor
Processor that replaces a pattern on the content of the created or updated files.
Warning
The files changed by this processor will not be committed to the git repository and will be discarded when the next deployment starts.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
✓ |
Regular expression to search in files |
|
|
✓ |
Expression to replace the matches |
|
|
|
Enables failing a deployment when there’s a processor failure |
Example
1- processorName: findAndReplaceProcessor
2 textPattern: (/static-assets/[^"<]+)
3 replacement: 'http://mycdn.com$1'
AWS Processors
All deployment processors related to AWS services support the following properties:
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
If not provided the AWS SDK default providers will be used |
The AWS Region |
|
|
The AWS Access Key |
||
|
The AWS Secret Key |
||
|
✓ |
AWS S3 bucket URL to upload files |
|
|
|
Enables failing a deployment when there’s a processor failure |
S3 Sync Processor
Processor that syncs files to an AWS S3 Bucket.
Example
1- processorName: s3SyncProcessor
2 url: s3://serverless-sites/site/mysite
S3 Deployment Events Processor
Processor that uploads the deployment events to an AWS S3 Bucket
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
|
URL of the deployment events file, relative to the local git repo |
Example
1- processorName: s3DeploymentEventsProcessor
2 region: ${aws.region}
3 accessKey: ${aws.accessKey}
4 secretKey: ${aws.secretKey}
5 url: {{aws.s3.url}}
Cloudfront Invalidation Processor
Processor that invalidates the changed files in the given AWS Cloudfront distributions.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
✓ |
List of distributions ids |
Example
1- processorName: cloudfrontInvalidationProcessor
2 distributions:
3 - E15UHQPTKROC8Z
Post Deployment Processors
The post deployment processors assume that all changed files have been handled and the result of the deployment is already known (either successful or failed) and take actions based on those results, because of that, these processors need to be placed after all main deployment processors to work properly.
File Output Processor
Post processor that writes the deployment result to an output CSV file under CRAFTER_HOME/logs/deployer for later access, whenever a deployment fails or
files were processed.
Example
1- processorName: fileOutputProcessor
Mail Notification Processor
Post processor that sends an email notification with the result of a deployment, whenever a deployment fails or files
were processed. The output file generated by the fileOutputProcessor is attached if it’s available.
Properties
Name |
Required |
Default Value |
Description |
|---|---|---|---|
|
|
The name of the Freemarker template used for email creation |
|
|
|
The value of the From field in the emails |
|
|
✓ |
The value of the To field in the emails |
|
|
|
The value of the Subject field in the emails |
|
|
|
Whether the emails are HTML |
|
|
Current local host name |
The hostname of the email server |
|
|
|
The date time pattern to use when specifying a date in the email |
|
|
|
Indicates for which deployment status emails should be sent |
|
|
|
Indicates for which deployment status emails should be sent. Possible values:
|
Example
1- processorName: mailNotificationProcessor
2 to:
3 - admin@example.com
4 - author@example.com
5 status: ON_ANY_FAILURE
Full Pipeline Example
The following example shows how the deployment processors work together to deliver a serverless site using AWS services.
1pipeline:
2 # -------------------- START OF MAIN PIPELINE --------------------
3
4 # First clone or update the local repository from github
5 - processorName: gitPullProcessor
6 remoteRepo:
7 url: https://github.com/myuser/mysite.git
8 branch: live
9 username: myuser
10 password: my_secret_password
11
12 # Then find the added/changed/deleted files since the previous pull (if any)
13
14 - processorName: gitDiffProcessor
15
16 # Change all references to static-assets to use a CDN URL instead of the local URL
17 - processorName: findAndReplaceProcessor
18 includeFiles: ['^/site/.*$', '^/templates/.*$', '^/static-assets/.*(js|css|html)$']
19 textPattern: (/static-assets/[^"<]+)
20 replacement: 'http://d111111abcdef8.cloudfront.net$1'
21
22 # Index the changes in search
23 - processorName: searchIndexingProcessor
24
25 # Sync the changes in a S3 bucket
26 - processorName: s3SyncProcessor
27 url: s3://serverless-sites/site/mysite
28
29 # Add a small delay to allow the S3 changes to propagate
30 - processorName: delayProcessor
31
32 # Invalidate the changed files in the CDN
33 - processorName: cloudfrontInvalidationProcessor
34 includeFiles: ['^/static-assets/.*$']
35 distributions:
36 - E15UHQPTKROC8Z
37
38 # Trigger deployment events so any Crafter Engine listening can update accordingly:
39 # Rebuild the site context if any config or script has changed
40 - processorName: fileBasedDeploymentEventProcessor
41 includeFiles: ["^/?config/.*$", "^/?scripts/.*$"]
42 excludeFiles: ['^/config/studio/content-types/.*$']
43 eventName: 'events.deployment.rebuildContext'
44
45 # Clear the cache if any static-asset has changed
46 - processorName: fileBasedDeploymentEventProcessor
47 excludeFiles: ['^/static-assets/.*$']
48 eventName: 'events.deployment.clearCache'
49
50 # Rebuild the GraphQL schema if any content-type has changed
51 - processorName: fileBasedDeploymentEventProcessor
52 includeFiles: ['^/config/studio/content-types/.*$']
53 eventName: 'events.deployment.rebuildGraphQL'
54
55 # Push the updated events to the S3 bucket
56 - processorName: s3SyncProcessor
57 includeFiles: ['^/?deployment-events\.properties$']
58 url: s3://serverless-sites/site/mysite
59
60 # -------------------- END OF MAIN PIPELINE --------------------
61 # Only Post Processors can be in this section
62
63 # Record the result of the deployment to a CSV file
64 - processorName: fileOutputProcessor
65
66 # Notify the site admin & an author if there were any failures during the deployment
67 - processorName: mailNotificationProcessor
68 to:
69 - admin@example.com
70 - author@example.com
71 status: ON_ANY_FAILURE
Custom Processors
Crafter Deployer can be easily configured to match different needs but in case additional features are needed it is also possible to include custom libraries by following this guide:
Step 1: Create the custom processor
Custom processors are completely free to use any third party library or SDK, the only requisite is to define a class
that implements the DeploymentProcessor interface.
Note
It is highly recommended to extend AbstractDeploymentProcessor or AbstractMainDeploymentProcessor instead of
just implementing the interface.
These classes can be accessed by adding a dependency in your project:
<dependency>
<groupId>org.craftercms</groupId>
<artifactId>crafter-deployer</artifactId>
<version>${craftercms.version}</version>
</dependency>
Step 2: Add the custom processor
Custom processors are included to the Crafter Deployer classpath by adding all the required jar files in the following folder:
INSTALL_DIR/bin/crafter-deployer/lib
Note
Make sure to carefully review all other dependencies in your project to make sure there are no conflicts with the libraries used by Crafter Deployer or any other custom processor.
Step 3: Configure the custom processor
Once the custom processor is placed in the classpath, the only remaining step is to create o update a target to use it. All configuration files for targets will be placed in the following folder:
INSTALL_DIR/data/deployer/targets
First you need to create or update a context file to define all beans required by the custom processor, the file should
be have the name {site}-{env}-context.xml:
<bean id="externalService" class="com.example.Service">
<property name="url" value="${service.url}"/>
<property name="port" value="${service.port}"/>
</bean>
<bean id="myCustomProcessor" class="com.example.CustomProcessor" parent="deploymentProcessor">
<property name="service" ref="externalService"/>
</bean>
Note
The parent bean is provided by Crafter Deployer and it includes common configuration used by the
AbstractDeploymentProcessor and AbstractMainDeploymentProcessor classes.
Once the bean has been defined it can be added to the target’s pipeline in the yaml file with the matching name
{site}-{env}.yaml:
target:
env: preview
siteName: mySite
deployment:
scheduling:
enabled: false
pipeline:
- processorName: myCustomProcessor
username: john
password: passw0rd!
service:
url: http://www.example.com
port: 8080
Any change in the classpath will require a restart of Crafter Deployer, changes in configuration files will be applied when the target is reloaded.
REST API
To view the Crafter Deployer REST APIs:
or in a new tabSource Code
Crafter Deployer’s source code is managed in GitHub: https://github.com/craftercms/deployer